 手机访问:wap.265xx.com
手机访问:wap.265xx.com计算机图形学领域还有哪些没有啃到肉的问题?
站在2019年来看:
计算机图形学还有哪些问题值得花费一个PhD周期去啃?在电影/游戏工业里,现有技术还有什么“势必要解决但暂未解决”的痛点?“图形学已死,SIGGRAPH日落西山“有没有道理?如果有道理,那么该从哪个角度来诠释这些说法?如果没道理,图形学要重新成为显学,要重新推动新的一波产业升级,要做出AlphaGo级别的工作,还有哪些潜在的大故事,是可能的潜力股?一个足够优秀的计算机图形学博士,需要具备哪些特别的、与其他计算机学科不同的技能点?这些技能点的培养,需要如何着力?技术元素在中国电影产业中的比重,未来会越来越大,还是越来越小?而中国电影/动画要真正走向世界,要真正产出足以载入世界电影史册的作品,在技术层面,我们和世界一流电影工业体系相比,还差什么?欢迎CGer热烈讨论!
There is only one heroism in the world: to see the world as it is, and to love it.— Romain Rolland, The Life of Michaelangelo (Preface)二十年前,图形学研究如火如荼,现在回归正常了,在某些人眼里就变成已死了。计算机理论顶会STOC、FOCS一年才三百多人,没人觉得是已死学科;网络顶会SIGCOMM一年也三百多人,没人觉得是已死学科;19年CVPR和NeurIPS暴涨也不过分别九千和一万五千人。SIGGRAPH这几年,虽然人数确实比十年前有所下降,但是参会人数都在15000-20000左右,19年是18000左右。放到整个CS学科里,算是最大的会议了。一个已死的学科会有这么多人感兴趣?
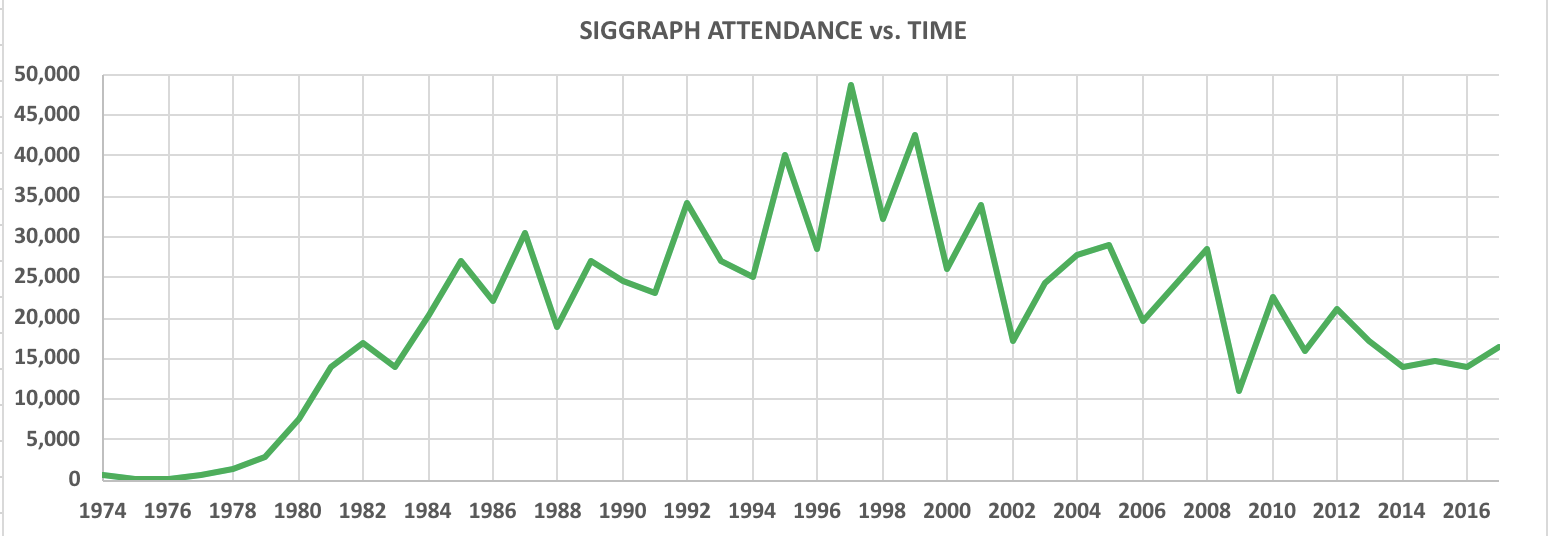 不同年份SIGGRAPH参与人数,来源:维基百科所谓图形学已死,其实就是一部分人追热点跑的比谁都快,觉得只要没有一帮VC在屁股后面追着的都是已死学科;另一部分人是受不住诱惑从图形学跳坑,然后看空图形学以彰显自己跳坑的明智。有些人会无视自己搞不定的问题以保护自己的自尊心,然后声称图形学已经没有什么问题需要解决了。最近两年经济不好,一大批靠PPT起家的公司垮了,一大堆追热门方向的调包侠找不到工作,于是一帮人开始喊深度学习已死了,诸神黄昏,灰飞烟灭了,其实也都是一个套路。
不同年份SIGGRAPH参与人数,来源:维基百科所谓图形学已死,其实就是一部分人追热点跑的比谁都快,觉得只要没有一帮VC在屁股后面追着的都是已死学科;另一部分人是受不住诱惑从图形学跳坑,然后看空图形学以彰显自己跳坑的明智。有些人会无视自己搞不定的问题以保护自己的自尊心,然后声称图形学已经没有什么问题需要解决了。最近两年经济不好,一大批靠PPT起家的公司垮了,一大堆追热门方向的调包侠找不到工作,于是一帮人开始喊深度学习已死了,诸神黄昏,灰飞烟灭了,其实也都是一个套路。
无论最上层的物理和几何模型有多么fancy,图形学的本质还是计算。从工业应用角度来看,目前比较高质量的物理模拟和渲染,计算都太慢。一般来说,电影级别的效果,都得上计算集群,而且动不动就跑好几天。数据量也太大,动不动一帧百GB。以毛发模拟为例,正常人头上有约10万根毛发,猫猫狗狗身上有上百万根毛发,而目前效果最好的毛发模拟方法跑30秒左右的10万毛发模拟所需计算时间就需要以天计,尤其是碰撞和摩擦。物理模型其实都不难,但是落实到数值算法上就有一堆的问题,时间步长、稳定性等等。
 2020年最精准的毛发和布料模拟,作者:Gilles Daviet @ Weta Digital而电影工业里,美术希望既能制作肉眼难辨,可能精确到微米级的细节,又希望一切都可调可交互(0.1-10帧/秒),而不是模拟、渲染只能提交集群和整个工作室的人一起排队用机时结果导演不满意打回去重跑;游戏工业里,3A的制作成本逐年提高,画质要求也是越来越精细,各种物理特效、全局光照、三角形数目不断狂增,可玩家要求的是实时(60帧/秒),而且不能说你只做一个效果、只在两千美元一块的高端显卡上实时。一般要求,模拟、绘制三角形、材质、光照、镜头、抗锯齿效果等等整体做到在中端显卡上甚至中高端手机上实时,这就要求一个效果在开发机上1ms以下。
2020年最精准的毛发和布料模拟,作者:Gilles Daviet @ Weta Digital而电影工业里,美术希望既能制作肉眼难辨,可能精确到微米级的细节,又希望一切都可调可交互(0.1-10帧/秒),而不是模拟、渲染只能提交集群和整个工作室的人一起排队用机时结果导演不满意打回去重跑;游戏工业里,3A的制作成本逐年提高,画质要求也是越来越精细,各种物理特效、全局光照、三角形数目不断狂增,可玩家要求的是实时(60帧/秒),而且不能说你只做一个效果、只在两千美元一块的高端显卡上实时。一般要求,模拟、绘制三角形、材质、光照、镜头、抗锯齿效果等等整体做到在中端显卡上甚至中高端手机上实时,这就要求一个效果在开发机上1ms以下。
这样的需求本身就是矛盾的,又要马儿跑,又不想给马儿吃草。说到底还是人类的计算能力太弱鸡。
这两年有一些用深度学习来加速模拟和渲染的尝试,以及做压缩的尝试。但是都还很初级,能加速的模型还非常有限,整体质量也和经典算法有差距。甚至对于很多问题,使用神经元网络还没有能在保证足够实际使用的泛化性的情况下性能超越经典算法的,尤其是在一些经典算法本身就可以看成是使用先验知识构造的网络的情况下。另外,有些传统算法的性能瓶颈,并不是使用了网络就能回避的。比如,在物理模拟领域,布料、FEM做的纯弹性体等具有明确、稳定拓扑结构的物体是比较适于用网络做加速的(GraphNet、MeshCNN等),而无明确拓扑的粒子模拟就很难:传统算法的瓶颈就在于为粒子建立明确拓扑结构(如MPM中将粒子映射到格子上,或者SPH中为粒子找最近邻),用网络也无法回避这一点。
业界很多时候希望一个特别难的问题能很快解决,但实际上,图形学作为一个已经趋于成熟的领域,很多问题需要很漫长的学术探索,并结合其他学科(数值分析、计算力学、微分几何、运筹学、机器学习等等)的最新成果,才接近有解决的可能。对于某些特别难的问题,这种状态可能会持续数年甚至十几年。
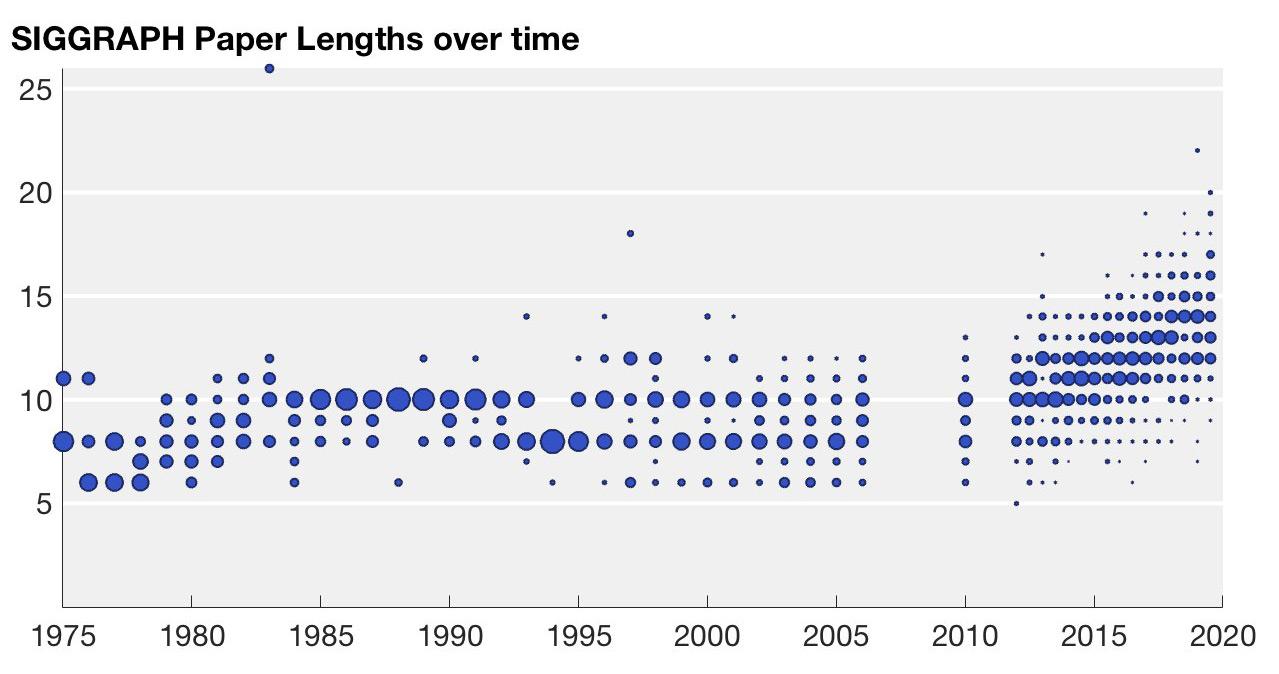 SIGGRAPH论文长度随年份的分布(Alec Jacobson)。人们对效果和性能要求越来越高,研究变得越来越难和复杂,这其中一个迹象便是,SIGGRAPH文章长度在最近几年一直在增加。而对于非关键需求,每年的研究成果又是供大于求的:比如想做一个小众的图形效果,要求不太高的话,可能有四五种技术路径、十几篇各有优劣的研究工作供开发选择。
SIGGRAPH论文长度随年份的分布(Alec Jacobson)。人们对效果和性能要求越来越高,研究变得越来越难和复杂,这其中一个迹象便是,SIGGRAPH文章长度在最近几年一直在增加。而对于非关键需求,每年的研究成果又是供大于求的:比如想做一个小众的图形效果,要求不太高的话,可能有四五种技术路径、十几篇各有优劣的研究工作供开发选择。
对于图形学的两大传统应用行业,影视和游戏,每年很多新的图形学技术可能要么应用范围很窄,要么因为种种局限性抵消了优势,总之对于现有业务降本增效影响不大。
因此,开发者的大部分精力放在了对现有技术的优化上。这也导致很多公司招图形学的人,实际上是在招会用游戏引擎,或者是熟悉D3D、Vulkan、Metal等API,以及熟练各种底层优化的人,和学术界的研究关系不大。并且,这两个行业很多地方的工资是出了名的低(尤其是欧美,而且越是高质量工资反而越低),中下层员工很多都是contractor(外包工身份),好多人医保都要纯自费。而一个在游戏行业有十几年3A开发经验的老兵,年薪可能还不如对冲基金一个本科刚毕业三四年的新人的一半。究其原因,这些地方普遍挣钱难,有情怀想做的人又多,导致公司营收与员工数量的比值较低。有人干了几年影视行业或者游戏,跳去citadel、2sigma搞算法交易或者去谷歌脸书搞后端开发,工资立刻翻了两三倍。
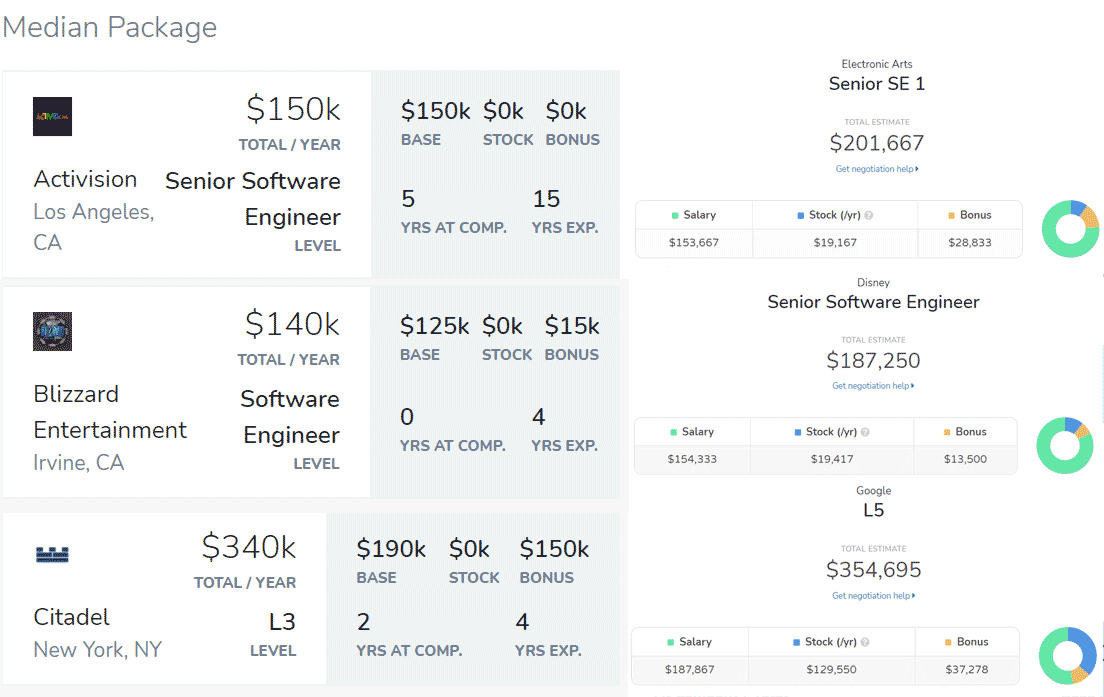 程序员(动视、EA、暴雪、迪士尼、Citadel、谷歌)中位年薪或类似工作年限年薪,来源:levels.fyi理想情况下,在学校、研究所的学者们做研究的初心是满足自己和同行的好奇心,并不需要搞清楚自己的研究能赚多少钱。纵观图形学发展史,我们会发现很难衡量一项研究带来的直接商业利润;而研究对产业发展的意义,更多在于拓展了业界未来的可能性。
程序员(动视、EA、暴雪、迪士尼、Citadel、谷歌)中位年薪或类似工作年限年薪,来源:levels.fyi理想情况下,在学校、研究所的学者们做研究的初心是满足自己和同行的好奇心,并不需要搞清楚自己的研究能赚多少钱。纵观图形学发展史,我们会发现很难衡量一项研究带来的直接商业利润;而研究对产业发展的意义,更多在于拓展了业界未来的可能性。
比如说,图形学近年来对于世界最大的贡献之一就是通用图形处理器(GPGPU)。今天,我们知道它是人工智能、数字货币等领域的基石。然而在其初始阶段,在04年NVIDIA押注BrookGPU并将其变成CUDA的时候,并没有人意识到它会有今日的影响力。黄仁勋自己也坦陈,为了支持CUDA,NVIDIA的GPU成本翻了一番,而在最初几年内并没有任何相关业务能带来相应营收,而后来人工智能领域的认可以及为NVIDIA带来的巨大收入更多是一个意外惊喜。
 Brook,CUDA的前身,发表于图形学顶刊ACM TOG,一作Ian Buck现为英伟达高性能计算部门经理我们可以看到,一项研究带来巨大商业价值是依赖了后续的工程投入和一些机遇的。同时,我们也很难预测一项研究到底给未来带来什么样的可能性。
Brook,CUDA的前身,发表于图形学顶刊ACM TOG,一作Ian Buck现为英伟达高性能计算部门经理我们可以看到,一项研究带来巨大商业价值是依赖了后续的工程投入和一些机遇的。同时,我们也很难预测一项研究到底给未来带来什么样的可能性。
当然,这并不是说我们没有什么可以做的了。一方面,在图形学的传统应用行业,游戏和电影特效,我们可以尝试找到边际利润更高的新的商业模式;另一方面,图形学从业者可以发掘一些有更多新需求,以及边际利润更高,同时图形学尚未广泛应用的行业,比如数字时尚、机器人、电子商务等等。这些行业的新需求能被图形学技术满足,便会有更多的资本投入计算机图形学这个领域,增加人们对这个领域的关注程度,从而引发图形学研究对未来产生更大贡献的可能性。
尤其对于学术界来说,这样才能吸引对于图形学领域的funding和高质量生源,提升每年SIGGRAPH文章的数量质量,解决更多的困难问题,在整个产学研的链条上形成正反馈。
这里会有一个向客户学习和不断迭代的过程。首先是充分和客户沟通,搞清楚客户的工作流程,以及要解决的问题、具体需求(以及需求优先级)和交付标准。然后为了适应这些新的需求、应用场景、工作流程,完成各种配套组件以打通数据流和让算法更好用,最终和用户协作完成业务的设计开发,甚至在一些没有配备美术、产品经理、客服的开发者团队中,开发者本人还可能需要兼任客服、美术外包的职位。
以上说的是全世界都有的问题。具体到中国来说,又涉及了一个图形学教育的问题,国内有能力接触前沿,能发SIGGRAPH的老师两只手就能数出来,基本就在那几所学校(北大、清华、浙大、中科、上科等等)。图形学又是个交叉学科,比如你要学物理模拟,除了得写一手好代码以外,连续介质力学、分析力学、数值计算都是基础,而绝大部分计算机系不可能开这些课。我在本科时候想搞物理模拟,结果根本搞不清楚该从哪里入门。整体下来,很多子方向国内没有综合性教材。这里郑重推荐一下GAMES系列(比如闫老师的GAMES101,https://sites.cs.ucsb.edu/~lingqi/teaching/games101.html,和胡老师的GAMES201,https://forum.taichi.graphics),是我见过最好的中文图形学课程了。
图形学里面是有核心底层问题没有解的,今天这里说说整个高真实感渲染领域悬而未决并且制约图形学发展的根本问题。
/* IDEA研究院(深圳)正在招C++做区块链/图形学/网络协议的小伙伴,和前微软全球执行副总裁沈向洋博士一起工作,实习,全职,远程都行,简历直接私信我哦,长期有效*/
在高真实感渲染领域,包括实时渲染(游戏),离线渲染(电影)以及下属的一堆子领域和课题,至今没有一个合理并且实用的渲染质量评价标准。我们没有一个合理实用的metric去评判渲染质量的好坏(人类视觉意义上的),当渲染出来的结果背离真实照片或者暴力物理模拟的结果时,缺乏有效的手段,认可哪些背离对人类视觉系统来说是不敏感的,哪些是不可容忍的。
我们需要定义一个更好的距离函数(或者叫相似性函数,或者叫误差度量函数,一回事儿),可以用来计算两张图片的距离,要求这个距离体现人类视觉心理层面的相似性。
这个事情直接关系到能否大规模地利用现在海量数据和算力推动学科发展。说出来很羞耻,在图形学领域,一个渲染算法如果有几个参数要调优,我们怎么办?就是手调,眼睛看呀!不像人家隔壁CV那样拉个数据集,可以全自动地狂跑数据,自动狂调。这就是为什么现代的机器学习方法没怎么在渲染领域用起来,因为没法用呀,loss function定义不出来 !
同时这个事情对减少学术界和工业界的隔阂至关重要,使得很多工业界的hack,有理论的依据。以后大家可以更愉快地hack各种绘制算法,并且有科学依据。也对一票的图像合成方向上的CV算法带来更具实际意义的指导。
这个距离函数现在不是没有,比如L2 distance,correlation等为基础的,有一堆常用的。这些本质都是线性度量,认为图像空间是线性的。这些度量在比对两张非常接近的图像是,是很有效的,因为非线性流型空间的无限小的局部子空间是线性的嘛。但是当两张图差距比较大的时候,这个线性近似就完全不靠谱了。很多时候,人类视觉看起来很严重的问题(比如不该有的边界,突变),用线性度量来算,发现误差很小,而有些人类视觉看起来差别不大的变化(如大面积的低频变化),在线性度量下误差非常大。
然后,就没有然后了 …… 我们现在没有更好的度量方案,任何问题都用线性近似硬刚了。这样的标准在有些领域是有效的,比如图像压缩,因为很多时候他们比对的图像本来就是极其相近的。但是在渲染领域,像素级一模一样代价极大,并且也是完全没有必要的,但是这是唯一的well-formulated的方法,只能用这个。然后分歧就来了,很多渲染学术工作不得不屈从这个标准去做,不计代价,而工业界很多有效的方法,在这个标准下其结果就很差,但其实人看起来挺好的。这个分歧是导致渲染领域学术界和工业界比较隔阂的重要因素。
这个问题有解吗?我觉得是有的,但是非常挑战。我们先可以看看隔壁听觉是怎么弄的。对于耳朵的听觉机理的研究,我们知道了人类听觉有截止频率,有相位不敏感性,这些都被用到声音压缩技术里面,并且有个很高端的名字,叫听觉心理学模型。视觉系统的前端早期感知研究也挺多的,比较成熟的比如色彩感知,所以我们知道没必要去刻画光谱,记录RGB三个响应曲线的积分值就好了,视觉也有截止频率即显示分辨率,但是和听觉不同,人的脑袋可以动,图像可以zoom,然后这些特性就没啥用。相位的局部变化(部分平移)对视觉来说是敏感的,而且当有参照物的时候很敏感。然后,更后期的感知,无论视觉和听觉的机理,都还没有什么成熟的东西可以用。
另一边,基于深度学习的CV算法浩如烟海,那边应该是可以得到很多启示的,但是罕有针对人类视觉本身的特性作为研究对象的。更多是假设了人类视觉的一些特性,然后去简化他们要解决的CV问题,也不知道这些假设是否靠谱。
深度学习的一些方法论是值得参考的,当我们无法直接研究一个对象的时候,我们就把他当成黑盒,大量收集这个对象的行为样本,然后用大规模的人工神经网络去近似它。这种反向工程的思路,可以帮助我们在搞清楚人脑是如何处理视觉信息之前,尝试建模人类的视觉感知行为。
要是有兴趣看的同学多,我再展开多讲讲。这个方向上一定是能出高质量的论文,SIGGRAPH及以上,前人也多多少少也有些探索和铺陈了。论文题目我都拟好了,Perceptual Image Similarity 。标题越短,事儿越大~ 大家有兴趣一起讨论讨论。
空间中多个互相遮挡的三角形,经过MVP变换与视口变换后,在光栅化过程中如何处理前后的可见性与遮挡问题。解决办法——深度缓冲(z-buffer)。
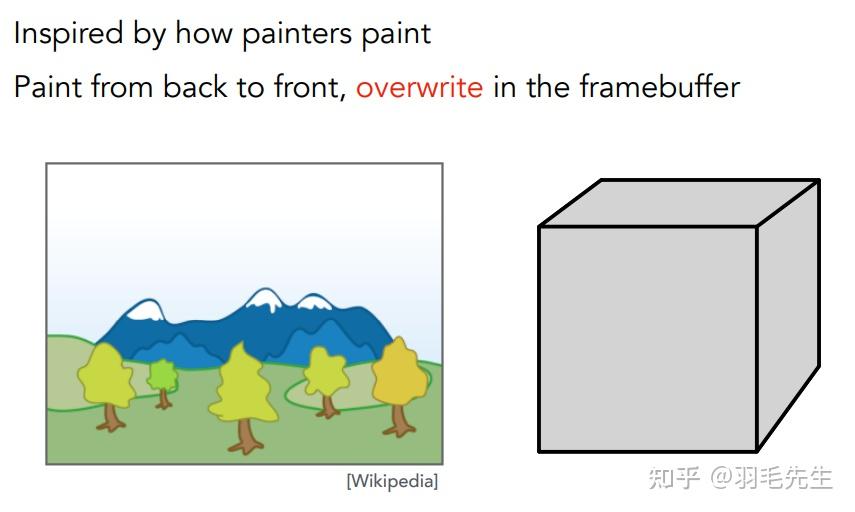 类比油画,先画远处的物品,再画近处的物品,覆盖之前画的内容。计算机实现:定义内容的深度,按照深度进行排序(复杂度nlogn),按照排序后顺序从远到近进行绘制。存在问题: 定义深度不容易排序有一定算力消耗无法解决循环遮挡问题。无法定义深度关系和排序。
类比油画,先画远处的物品,再画近处的物品,覆盖之前画的内容。计算机实现:定义内容的深度,按照深度进行排序(复杂度nlogn),按照排序后顺序从远到近进行绘制。存在问题: 定义深度不容易排序有一定算力消耗无法解决循环遮挡问题。无法定义深度关系和排序。 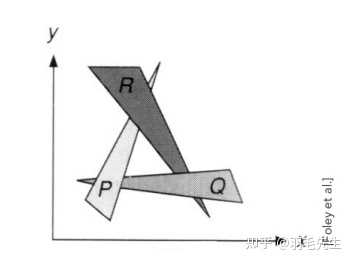
「因此无法使用画家算法解决遮挡问题。」
Z-buffering相较画家算法而言更加适用,因为它是按像素的深度大小进行排序。(实际上并无进行排序计算,只是通过记录的方式效果上实现了排序)
深度: 物品上的某一点与相机的距离,数值越大,距离相机越远。对屏幕中的每一个像素P
初始定义深度值为无穷大(距离相机无限远)。在对每个物体的每一个像素A进行光栅化时 ,判断A的深度值(DepthA)与同一位置P(DepthP)处存储的深度值的大小关系: 如果比”当前已绘制像素记录的深度值“小,则绘制像素,同时更新深度值,并用DepthA更新当前DepthP的值如果比”当前已绘制像素记录的深度值“大,则不绘制像素,也不操作深度值DepthP 「如果应用msaa算法,则不是在一个像素内,而是在一个像素内取多个采样点,然后每一个采样点进行深度缓冲,效果会更好」
「如果应用msaa算法,则不是在一个像素内,而是在一个像素内取多个采样点,然后每一个采样点进行深度缓冲,效果会更好」
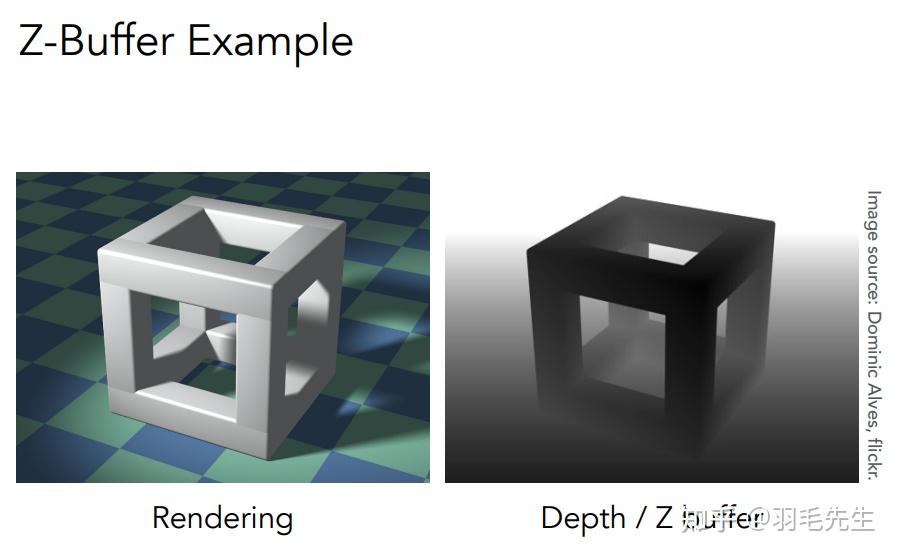 同步生成渲染图与深度图离摄像机越近,深度值越小,画面上越黑离摄像机越远,深度值越大,画面上越白
同步生成渲染图与深度图离摄像机越近,深度值越小,画面上越黑离摄像机越远,深度值越大,画面上越白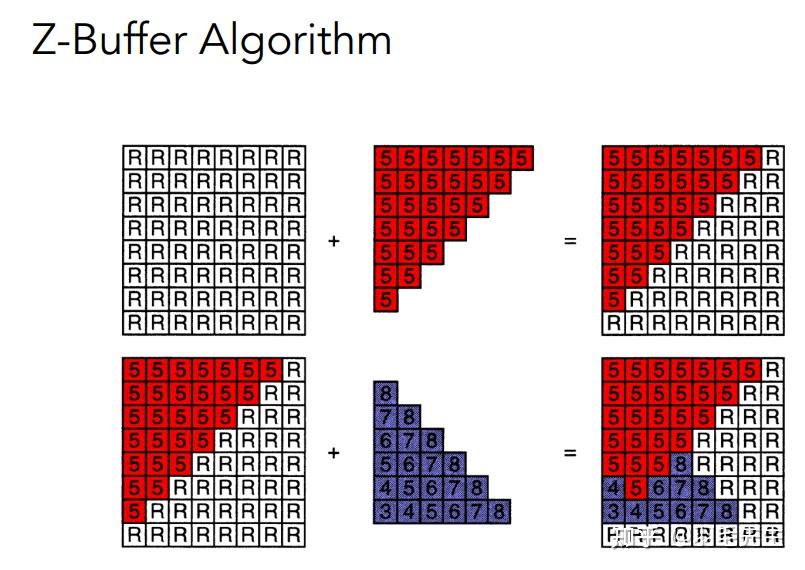 首先定义屏幕上所有像素的深度为无穷大渲染红色像素,由于初始为无穷大,所有红色像素都需要渲染。渲染蓝色像素时,需要判断深度大小关系来决定是否渲染。算法没有进行排序,只是记录当前所绘制像素的最小值,因此算法复杂度为O(n)对绘制顺序无要求。说明: 无法处理透明物体,需要特殊处理。
首先定义屏幕上所有像素的深度为无穷大渲染红色像素,由于初始为无穷大,所有红色像素都需要渲染。渲染蓝色像素时,需要判断深度大小关系来决定是否渲染。算法没有进行排序,只是记录当前所绘制像素的最小值,因此算法复杂度为O(n)对绘制顺序无要求。说明: 无法处理透明物体,需要特殊处理。
一个空间中的三角形:
1.经过MVP变换后,视锥变成了的标准立方体(Canoniacal Cube),视锥内的三角形同步变换。2.再经过视口变换,立方体变换为(0,0)为原点,长宽为(width,height)的屏幕空间下的矩形,三角形同步应用变换。3.最后在屏幕上的每一点进行采样,则可以将空间中的三角形在屏幕上显示出来了。以上过程是绘制一个三角形的过程。当绘制多个三角形时,则需要处理它们的前后关系,采用”深度缓冲“处理是非常好的方法。深度缓冲其实就是对每个像素求最小值。
关注公众号“羽毛不会飞”,后台回复“计算机图形学”,获得虎书第二版中文版,虎书第四版英文版,games101课件
「"文末喜欢作者"——投喂羽毛小鸡腿 ,吃饱了继续写。」

「点点广告也是爱 ,攒攒明年植发钱。」
现代计算机图形学入门-L6-光栅化.2-反走样与滤波
现代计算机图形学入门-L5-光栅化.1-视口变换与光栅化过程
现代计算机图形学入门-L4-变换.2
现代计算机图形学入门-L3-变换.1
现代计算机图形学入门-L2 ——线性代数
现代计算机图形学入门-L1
另辟蹊径的"一键打包"
Web/Native资源加密方案
Spine换装方案多平台解析
基于creator3.0的3D换装
CocosCreator3.4.2原生二次开发的正确姿势——手把手教你接SDK
在编辑器上声明自定义数据数组
包体优化指南
不规则3D地形行走
快速实现3d抛物线绘制
奇形怪状-不规则按钮实现
我是羽毛,一名游戏研发工程师,一名野生摄影同学。我的公众号主要分享自己的一些游戏项目开发过程中的功能总结及日常开发笔记。也希望能通过平台的交流,与更多有想法的同学交流认识,共同成长。
欢迎大家在日常开发过程中,如果觉得有需要讨论解决、分享或者探讨的内容,在公众号后台或者文章留言处给我反馈,提供写作的方向,从另一个角度也尽量让写作内容更贴近大家的需求以及痛点,在此谢谢各位同学.
「另外羽毛也提供付费技术咨询的服务,有需求的同学可以公众号后台私信添加微信。」
 更多精彩欢迎关注微信公众号“羽毛不会飞”
更多精彩欢迎关注微信公众号“羽毛不会飞”
DDGI
Morgan McGuire 在2017年提出的 Precomputed Light Field Probes[1]将场景的光照信息和几何信息编码进了新的数据结构 light field probes。
该数据结构根据存储内容的不同可以分为 radiance light field probe 和 irradiance light field probe:
radiance light field probe 根据环境光照得到各个方向的 radiance 、normal 、radial distance ,并通过发射光线为 irradiance light field probe 提供 incident radiance 。irradiance light field probe 接受了来自各个方向的 incident radiance ,并为每个 texel 过滤得到irradiance。此外通过保存 radial depth 以及 squared radial depth 为后续着色过程中的采样提供了visibility-test 的依据。该数据结构和论文的详细内容分析可见相关专栏文章[2]。
Zander Majercik 在上述工作的基础之上,于2019年提出了 Dynamic Diffuse Global Illumination with Ray-Traced Irradiance Fields[3]。
该论文在 light field probes 数据结构基础之上,为解决 leaks 和 dynamic 作出了以下贡献:
dynamic:
为了应对动态的几何物体和光线,每一帧对场景中的 个活动探针根据随机序列发射
条光线。对探针发出的每一条光线进行追踪,对光线与场景的各个相交点进行着色计算得到 radiance。在空间域上,对探针的每个 texel,计算其半球内发射光线与场景相交点的 radiance 对于新一帧 irradiance 的贡献,过滤得到当前帧的 irradiance;并结合上一帧已保存的 irradiance,在时域上混合得到当前帧最终的irradiance 。该更新算法将 irradiance 信息压缩进了多个低分辨率的 irradiance probes 中,避免了对高分辨率场景球形纹理的降噪和预过滤(independent of framerate and screen resolution),从而实现了对场景中几何物体和光线动态变化的表现。leaks:
存储用于防止 leaking of light and shadow 的 visibility information 。在着色的采样阶段进行空间域上的 trilinear interpolation(结合来源于 visibility information 的occlusion)进行 irradiance queries,从而应对场景在时域上不断变化的几何物体和动态光线。该论文的详细内容分析可见相关专栏文章[4]。
Zander Majercik 在之前工作的基础上,于2021年提出了 Scaling Probe-Based Real-Time Dynamic Global Illumination for Production [5],对 DDGI 的实现细节提出了各种优化和改进。
以 DDGI 为核心算法,NVIDIA 利用 GPU ray tracing 提出并实现了 RTX Global Illumination (RTXGI) 算法,以下是相关引用:
RTXGI github[6]。RTXGI DDGIVolume[7] 。RTXGI Integration[8]。RTXGI SDK[9]。RTXGI Test[10]。整个 RTXGI 的项目工程可解耦成 test-harness 和 RTXGI SDK ,但核心流程都与下图的时间轴直接对应:
 ddgivolume nsight scrubberTrace Probe Rays - RayTraceVolumes (test-harness) / GetRayDispatchDimensions (RTXGI SDK) 。Update Probes - Execute (test-harness) / UpdateDDGIVolumeProbes (RTXGI SDK) 。Relocate Probes - Execute (test-harness) / RelocateDDGIVolumeProbes (RTXGI SDK) 。Classify Probes - Execute (test-harness) / ClassifyDDGIVolumeProbes (RTXGI SDK) 。Query Irradiance - GatherIndirectLighting (test-harness) 。其中,DDGIVolume 是整个 RTXGI 算法的核心数据结构,它直接定义了整个 3D grid-space 的探针空间,并保存了算法各个阶段的纹理数组 (在后文会依次介绍):
ddgivolume nsight scrubberTrace Probe Rays - RayTraceVolumes (test-harness) / GetRayDispatchDimensions (RTXGI SDK) 。Update Probes - Execute (test-harness) / UpdateDDGIVolumeProbes (RTXGI SDK) 。Relocate Probes - Execute (test-harness) / RelocateDDGIVolumeProbes (RTXGI SDK) 。Classify Probes - Execute (test-harness) / ClassifyDDGIVolumeProbes (RTXGI SDK) 。Query Irradiance - GatherIndirectLighting (test-harness) 。其中,DDGIVolume 是整个 RTXGI 算法的核心数据结构,它直接定义了整个 3D grid-space 的探针空间,并保存了算法各个阶段的纹理数组 (在后文会依次介绍):
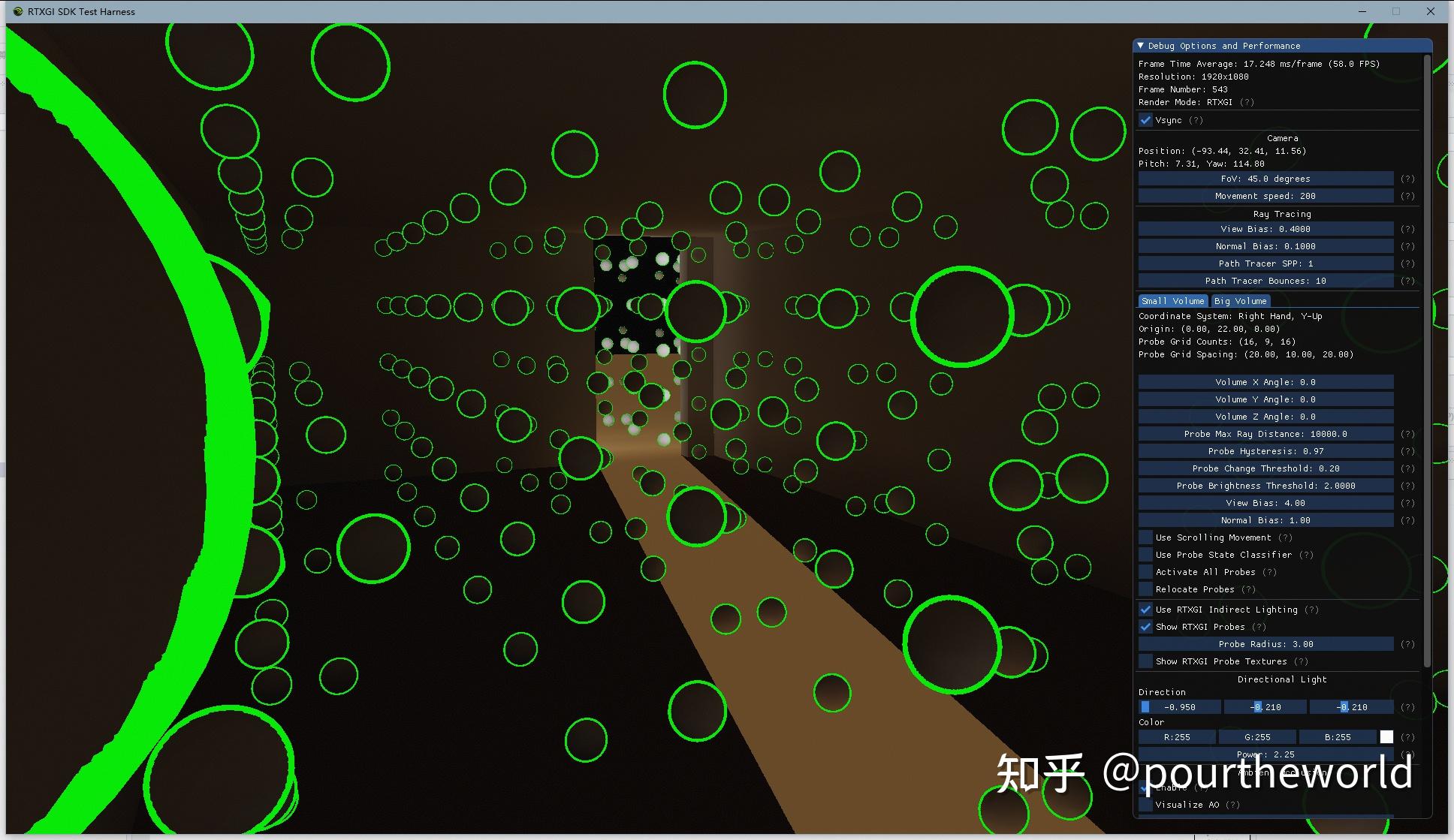 RTXGI SDK Test-Harness 3D grid-space本文篇幅有限,对于 RTXGI 实现中的 Infinite Scrolling Movement 以及可选项 Probe Variability 不会详细展开介绍,感兴趣的读者可自行阅读代码分析。
RTXGI SDK Test-Harness 3D grid-space本文篇幅有限,对于 RTXGI 实现中的 Infinite Scrolling Movement 以及可选项 Probe Variability 不会详细展开介绍,感兴趣的读者可自行阅读代码分析。
接下来,本文将对 RTXGI 五个核心阶段的算法和实现进行详细介绍:
第一部分,介绍 DDGIVolume 中每个 active probe 的 Trace Probe Rays 阶段,最终获取保存了 incident radiance 和 radial distance 的 Probe Ray Data 纹理数组。第二部分,介绍 DDGIVolume 中每个 active probe 的 Update Probes 阶段,最终获取保存了 irradiance 和 radial depth / radial squared depth 的 Probe Irradiance and Distance 纹理数组。第三部分,介绍 DDGIVolume 中可选的 Relocate Probes 阶段,调整每个探针的世界坐标,更新 Probe Data 纹理数组的 XYZ 通道。第四部分,介绍 DDGIVolume 中可选的 Classify Probes 阶段,对每个探针进行分类,更新 Probe Data 纹理数组的 W 通道。第五部分,介绍 DDGIVolume 最终的 Indirect Lighting 阶段。参考Tracing Probe Rays 从 DDGIVolume 中,收集来自所有活跃探针周围环境的 radiance 和 radial distance (定义可见前文 Radial Gaussian Depth ) 到2D纹理数组 RayData 中。
关于 Probe Ray Data 纹理数组布局引用于 Probe Ray Data,该纹理数组由垂直于坐标系上轴的探针平面 (slices) 构成:
 The Probe Ray Data texture array (all slices) from the Cornell Box scene而纹理数组每个 slices 的 row 对应了探针平面的探针索引,column 则对应了该探针索引对应探针发出的其中一条光线索引,每个 texel 最终保存了第 row 个探针发射出 第 column 条光线后,相交于某个最近平面的 distance 以及收集到的 incoming radiance:
The Probe Ray Data texture array (all slices) from the Cornell Box scene而纹理数组每个 slices 的 row 对应了探针平面的探针索引,column 则对应了该探针索引对应探针发出的其中一条光线索引,每个 texel 最终保存了第 row 个探针发射出 第 column 条光线后,相交于某个最近平面的 distance 以及收集到的 incoming radiance:
 The Probe Ray Data texture (zoomed, brightened) from the Cornell Box sceneRayData 所用的纹理坐标对应代码 DDGIGetRayDataTexelCoords :
The Probe Ray Data texture (zoomed, brightened) from the Cornell Box sceneRayData 所用的纹理坐标对应代码 DDGIGetRayDataTexelCoords :
rayIndex - 探针光线索引。probePlaneIndex - 探针所在平面索引。probeInPlaneIndex - 所在平面内探针索引。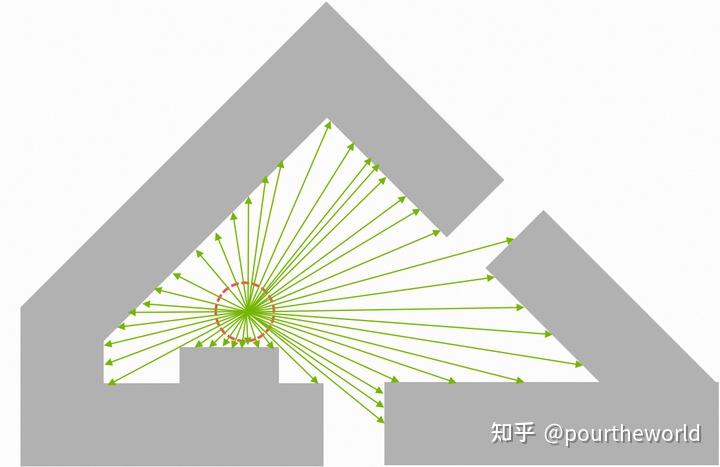 n ray casts of a probeProbe rays 通过 ray generation shaders RayGen() 通过 dispatch 得到,该 shader 会依次执行以下步骤:
n ray casts of a probeProbe rays 通过 ray generation shaders RayGen() 通过 dispatch 得到,该 shader 会依次执行以下步骤:
获取来自 DDGIVolume 的常量。加载探针状态。追踪光线。处理光线 miss 和 backface hits 。对 frontface hits 计算 direct lighting 。对 ray hit location 周围8个最近探针的 irradiance 进行采样,并计算 indirect lighting 。计算并保存该方向的 radiance 和 radial distance 到 RayData 中。其中,本文着重分析 irradiance 采样部分 (适用于 trace probe rays 和 query irradiance 两个阶段),以下截取自 RayGen() :
在进入 DDGIGetVolumeIrradiance() 的分析之前,首先介绍与其相关的三个参数 ray.Direction, surfaceBias, volumeBlendWeight 。
前文 DDGI Generating and Tracing Probe-Update Rays 曾提到,根据stochastically-rotated Fibonacci spiral pattern 均匀采样 个方向,并从当前 probe center 发射出
条光线。
工程代码 RTXGISphericalFibonacci() 将随机采样得到的射线方向转换成世界坐标下的 ray.Direction 返回:
其中 是probe center所在半球的z轴,
约等于
。
前文 DDGI Indirect Interpolation and Sampling 曾提到,需要根据着色点的法线和观察方向等比例添加一个normal offset bias 。
论文 4.1 Self-shadow Bias of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production 详细地解释了这一点:当查询 DDGIVolume 表面上的某个探针的信息时,可见信息 的 variance 在表面最大。为了避免由此导致的阴影泄漏,在探针查询期间需要向采样点添加额外偏差。
但实际的实现中并没有采用论文的方案,只是简单的计算得到 surfaceBias 。
surfaceBias 依赖的参数分为两种情况:
Tracing Probe Rays - cameraDirection 为探针发出射线的方向, surfaceNormal 为探针发出射线击中点的表面法线方向。Query Irradiance - cameraDirection 为摄像机观察方向, surfaceNormal 为待着色点的表面法线方向。DDGIGetVolumeBlendWeight() 帮助在多个 DDGIVolume 和/或未被 DDGIVolume 覆盖的区域间进行混合。
这里我们只讨论 volume 和 non-volume 区域之间的混合:给定 volume 内的所有位置的权重为1,而 volume 外的位置的权重为[0,1], 该权重随着位置远离 volume center 而减小:
接下来两小节将详细介绍 DDGI 的 Irradiance Integration 和具体的 Irradiance Query 。
以下内容引用于 DDGI Irradiance Integration 。
回顾 Irradiance 和 Radiance
在 Radiometry 的定义[11][12]:
Irradiance: 到达某个辐射 surface 的, per unit area 的 flux of radiant energy 。Radiance: 沿着某个 direction 的,per projected unit area, per unit solid angle 的 flux of radiant energy 。为了计算 Irradiance[13] 在 shading point 上半球的所有方向 上计算 incident radiance。
对于任意 normal 为 的 shading point
的 irradiance
:
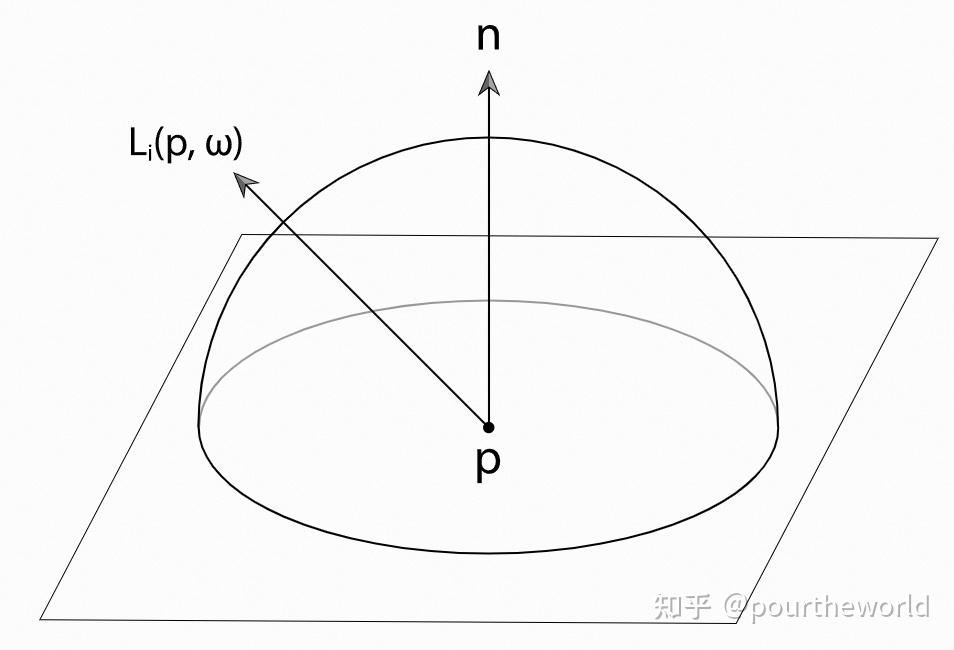 Irradiance at a point p is given by the integral of incoming radiance times the cosine of the incident direction over the entire upper hemisphere above the pointDDGI 使用 General Monte Carlo Estimator (uniformly sampling)[14] 对 irradiance 近似,其中
Irradiance at a point p is given by the integral of incoming radiance times the cosine of the incident direction over the entire upper hemisphere above the pointDDGI 使用 General Monte Carlo Estimator (uniformly sampling)[14] 对 irradiance 近似,其中 是上半球投影到表面后的积分区域,
是 incident radiance 的采样数量:
DDGI 的每个 irradiance probe texel 存储了由球面的八面体参数化定义的[15],表面法线为 的某个点
的 Monte Carlo Estimator 近似结果 (Irradiance Approximation) ,注意此处为了计算效率将
暂时移出等式:
为了减少存储在探针中 irradiance estimate 的 variance,DDGI 将 incident radiance 之和除以 cosine weights 之和(而不是 incident radiance 的采样数量):
由于采样是均匀的,cosine weights 可以计算期望值:
DDGI 进一步对
计算期望值:
DDGIGetVolumeIrradiance() 会在最后补上 :
需要注意的是,在实际接口中 的值并没有通过期望值计算,而是通过上述介绍中累积 cosine weights 得到。
前文 Probe Surfel Shading 中提到,probe updates和final rendering使用同一个 shading model,均为采用最新方案的 direct illumination pass 和使用 probe data 的 indirect lighting pass,这里我们仅讨论 indirect illumination 所需要的 irradiance 。
其中, DDGI 在 final rendering 阶段计算 irradiance 时,通过引入 backface-cull, visibility-test, normal offset ,从而不断完善在某一方向上,来自 shading point 所在 DDGIVolume 活跃探针的 outgoing radiance ,在计算该 shading point irradiance 时所占的 weights。
类似的,DDGI 在 trace probe rays 阶段,发出某个方向的射线并击中场景中某个 hit point 。为了得到来自该方向的 incident radiance 以便后续探针的更新,同样需要使用上述的 shading model 。
trace probe rays 阶段计算 irradiance 的过程也与 final rendering 类似,都是对某个点所在8个最近探针的 irradiance 采样得到 outgoing radiance,再根据 weights 计算 irradiance。区别在于计算 irradiance 所需要的方向 ,前者为 hit point 的 normal 方向,而后者为 shading point 所在表面的 normal 方向。
清楚了两个阶段计算 irradiance 的异同点后,接下来详细分析 DDGIGetVolumeIrradiance() 。滤去变量初始化和坐标转换的相关代码,直接进入 hit point 点8个最近探针 irradiance 采样和 weight 计算的迭代过程。
在进入迭代之前,需要预先计算几个必要变量:
biasedWorldPosition - hit point 在加上 surfaceBias 以后的世界位置。baseProbeCoords - 离当前 hit point 最近的探针的格子坐标。alpha - hit point 与 最近探针之间的距离除以整个 probe 空间的大小,并在三个方向上归一化到[0, 1] 。进入迭代,从最近探针获取当前探针,并计算得到采样当前探针 radial distance 和 irradiance 所需相关参数:
adjacentProbeOffset - 当前探针与最近探针之间的格子坐标偏差,用于计算 trilinear weight 。adjacentProbeWorldPosition - 当前探针的世界位置。worldPosToAdjProbe - hit point 到当前探针的方向。biasedPosToAdjProbe - 偏移过后 hit point 到当前探针的方向。biasedPosToAdjProbeDist - 偏移过后 hit point 到当前探针的距离。基于 hit point 到各个探针的距离计算各个探针的 trilinear weight :
DDGI 使用了一个相对平滑的 backface-cull ,使得某些与光线方向(此处为 hit point normal)点乘为负的 worldPosToAdjProbe 依旧能提供部分 outgoing radiance,这在一个内部的场景尤为有效(不存在阴影泄露)。此外,为了减少当两个方向完全相反导致 weight 为0的情况,加上适当的偏移:
接下来 DDGI 继续进行 visibility-test (可见前文Radial Gaussian Depth) 。
上文已经介绍过 surfaceBias 对于 visibility-test 的意义,因此根据 biasedPosToAdjProbe 偏移过后的方向得到当前探针八面体对应 texel 的坐标,并采样得到对应的 radial depth 和 radial squared depth,最后根据 chebychev visibility test 得到 chebyshevWeight 。
需要特别的是,filteredDistance 额外乘了2倍,这一点在下文 Update Probes 的 Update Depth 部分会给出解释。
人类视觉系统对光线变暗十分敏感,即人眼感受到的黑暗程度实际上大于光强降低的程度。为了模拟这种情形,DDGI 在5.2 Diffuse Indirect Illumination of DDGI paper 引入一个了感知权重:通过一条单调递减曲线将较低的权重进一步减少:
计算完权重后,根据 direction (hit point normal) 对当前探针的 irradiance 进行采样,获取当前探针在该方向上的 outgoing radiance :
论文 4.2 Perception-based Exponential Encoding of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production 提到为了解决 irradiance 缓慢收敛时造成 diffuse indirect illumination 的明显滞后 (尤其时由明转暗时),实际工程通过改变 gamma 值来加速收敛。
由 Gamma Correction 可知,现代渲染管线中用于 gamma correction decoding/encoding 的 gamma 值一般为 2.2。
实际工程经过检验将其设为了5,在 Irradiance Query 阶段实际上需要先将保存在 probe sRGB 线性空间的值 decoding 到 gamma 空间 ,如以下代码所示默认 decoding 的 gamma 值为 5.0 * 0.5 = 2.5:
最后将 irradiance (outgoing radiance) 乘上 weight 后累加,并且 weight 本身也需要累加 (见前文 Irradiance Integration) :
退出迭代,通过累加后的 weight 对 irradiance 进行归一化,乘上 Monte Carlo Estimator 需要的积分区域 ,最后注意为了光照着色需要将 irradiance 从 gamma 空间转回 sRGB 线性空间 :
经过 Tracing Probe Rays 阶段,当前 DDGIVolume 将活跃探针各个光线方向上的 radiance 和 radial distance 信息保存到了 RayData 中。
接下来,Update Probes 阶段以每个探针各个 texel 作为 irradiance 的 ,获取来自 RayData 所有方向上的 radiance 和 radial distance 。并对已保存的信息进行更新:
对于 radial distance 和 radial squared distance 乘上权重和简单求和得到 radial depth 和 radial squared depth 。对于 radiance ,不仅需要考虑权重,还需要从空间域和时域上考虑上一帧 irradiance 和当前帧 radiance 在当前帧 irradiance 中的占比。这一部分的理论内容可见前文 Probe Surfel Updates ,irradiance 主要插值公式为:
更新后的 irradiance 和 depth 信息最终会被保存到 Probe Irradiance and Distance Texture Arrays 中。
类似于上文提到的 Probe Ray Data 纹理数组,该纹理数组的 slices 同样表示垂直于坐标系上轴的探针平面。
不同的是,每个 slices 中的 row 和 column 由 3D grid-space 坐标经过 octahedral parameterization[16] 后以 Octahedral map 的形式表示:
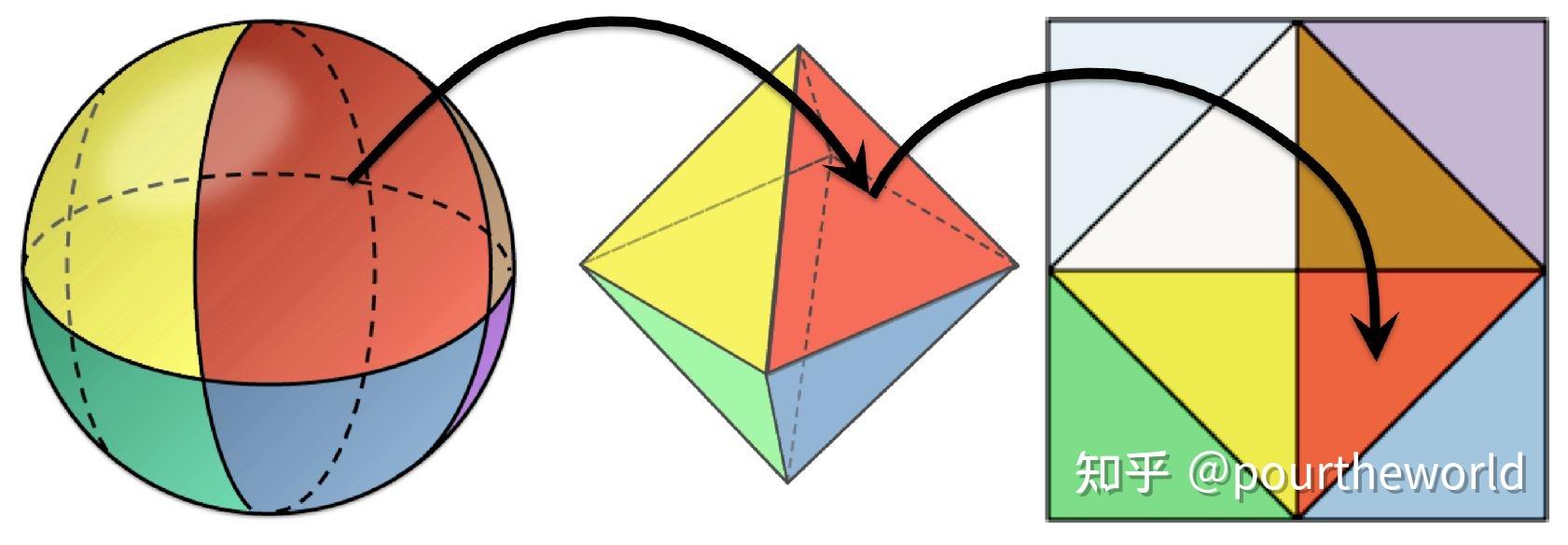 Octahedral parameterization of a sphere在本专栏 Octahedron Projection 提到过 Octahedral map 经过二次投影后将上半球和下半球分别保存到了纹理的中心部分和边缘部分。此外,为了支持边缘部分的 bilinear sampling,额外添加了 1-texel 的边界:
Octahedral parameterization of a sphere在本专栏 Octahedron Projection 提到过 Octahedral map 经过二次投影后将上半球和下半球分别保存到了纹理的中心部分和边缘部分。此外,为了支持边缘部分的 bilinear sampling,额外添加了 1-texel 的边界:
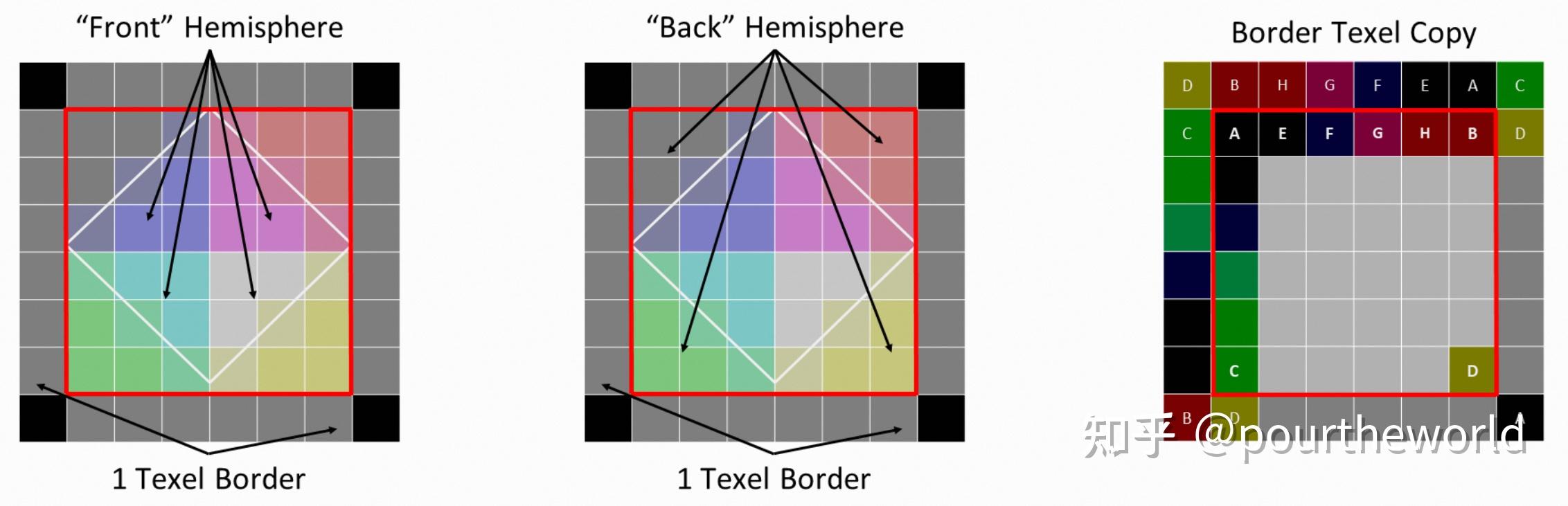 Octahedral map interior and border texel layout因此,在当前纹理数组的其中一个 slice 中,row 和 column 对应了该 slice 对应探针平面上每个探针在 3D grid-space 中的位置索引乘上 Octahedral map (6x6) 的坐标。每个 texel 保存了对应的 irradiance 以及 depth 的计算结果:
Octahedral map interior and border texel layout因此,在当前纹理数组的其中一个 slice 中,row 和 column 对应了该 slice 对应探针平面上每个探针在 3D grid-space 中的位置索引乘上 Octahedral map (6x6) 的坐标。每个 texel 保存了对应的 irradiance 以及 depth 的计算结果:
 Irradiance (top) and distance (bottom) probe atlases for the Cornell Box scene
Irradiance (top) and distance (bottom) probe atlases for the Cornell Box scene
接下来两个小节将分别介绍 depth 和 irradiance 的更新,具体工程代码位于 UpdateDDGIVolumeProbes ,具体 shader 代码位于 DDGIProbeBlendingCS 。
回顾 Chebychev Visibility Test[17] 所需要的 Mean 和 Variance , 实际上只需要对 radial distance 和 radial squared distance 乘上权重并简单求和即可获取 radial depth 和 radial squared depth :
Mean: .Variance:
.Chebychev Visibility Test:
.Radial Distance:
.Radial Depth:
.以下代码分析中滤去了各类变量声明和调试信息,并统一采用了宏的其中一个分支,仅保留核心算法部分。
首先根据 dispatch 的全局信息获取当前探针索引,经过八面体展开后得到当前 probe texel 的纹理坐标,并以此获取对应的由 probe center 发出射线在世界坐标系下的方向 probeRayDirection :
接下来进入迭代,将依次计算 RayData 中每条光线对于 radial depth 和 radial squared depth 的贡献。
其中,depth 和 irradiance 在计算时有一个共同权重:即,当前更新探针 texel 对应的方向 probeRayDirection 与 RayData 当前迭代光线方向 rayDirection 的点乘。
此外,为 depth 作出贡献的 distance 不能是无限远的,实现中将其限制在当前探针空间的1.5倍以内。
注意,result 变量分别保存了 乘以权重后的 distance,乘以权重后的 squared distance,以及 weight 。
计算完所有 RayData 保存的 radial distance 对 radial depth,radial squared depth 作出的贡献后,退出迭代,并根据上文 Irradiance Integration 中提到的 Monte Carlo Estimator 除以累加后的权重。但当前代码与注释有逻辑相悖之处:
根据上文论证,通过除以 sum of cosine weights 代替除以 the number of radiance samples
,可以减少 variance。由于采样均匀,可以简化 sum of cosine weights 为期望值
。如果使用此期望值,则最后计算时需要乘以
,与
相乘约去得到
。而注释中提到,由于 distance 不同于 irradiance,并没有使用 sum of cosine weights ,但为了与 irradiance 的情况保持一致从而使得 shader 不进行切换,于是在上文中提到的 Irradiance Query 阶段对 filteredDistance 额外乘2。之所以说逻辑相悖,是因为代码实际上在 distance 的计算中也使用了 sum of cosine weights 代替 the number of radiance samples,因此笔者认为此处可能是个错误,欢迎批评指正。
除此之外,根据预设的 hystersis 与前一帧的 radial depth,radial squared depth 插值得到最后的结果。
更新 Irradiance 与更新 Depth 在权重、插值方面基本类似,本小节会在进入迭代前、迭代中、迭代后的不同之处加以分析。
以下代码中可以发现,在更新 irradiance 的过程中可以通过引入 maxBackfaces 最大背面的数量,从而为 irradiance 引入 local occlusion 的信息。
当 probeRayDistance 小于 0 的次数 (当前射线在 Trace Probe Rays 阶段与场景中某个物体的背面相交) 超过 maxBackfaces 时,当前的 radiance 便不再计入计算 irradiance 的贡献中:
退出迭代,首先要将 线性 sRGB 空间中的 result 值通过预设的 gamma 值 (5.0),encoding 到 gamma 空间进行保存。这里使用远大于传统 2.2 的 5.0 gamma 值是为了让 irradiance 快速收敛:
最后,论文 4.3 Fast Convergence Heuristics of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production 通过修改 hysteresis 在时域上加速 irradiance 的收敛。
hystersis 作为插值的一部分,值越大意味着前一帧 irradiance 占比更大,反之当前帧 irradiance 占比更大。
在实际工程中,若当前帧 irradiance 的值或者转为 luminance 后的结果与上一帧结果的差 delta ,超过 probeBrightnessThreshold 或者 probeBrightnessThreshold 两个阈值时,意味着 hystersis 应该变得更小,即,当前帧的占比应该更大:
本节和下节作为算法的优化环节,在实际实现中通过开关控制是否开启。
在前文的分析中提到,探针的 visibility information 用于防止被遮挡的探针提供额外的 light/shadow 导致泄露问题。但是在某些情况下,完全被遮挡的探针会长时间被忽略,从而在实际着色阶段被排除在外,这对于位于几何体内部的探针尤为明显。
下图可知,初始阶段部分探针被嵌在墙内或者在 DDGIVolume 外部,前者导致部分探针永远不会对最终成像作出贡献,后者则在角落处泄露了阴影:
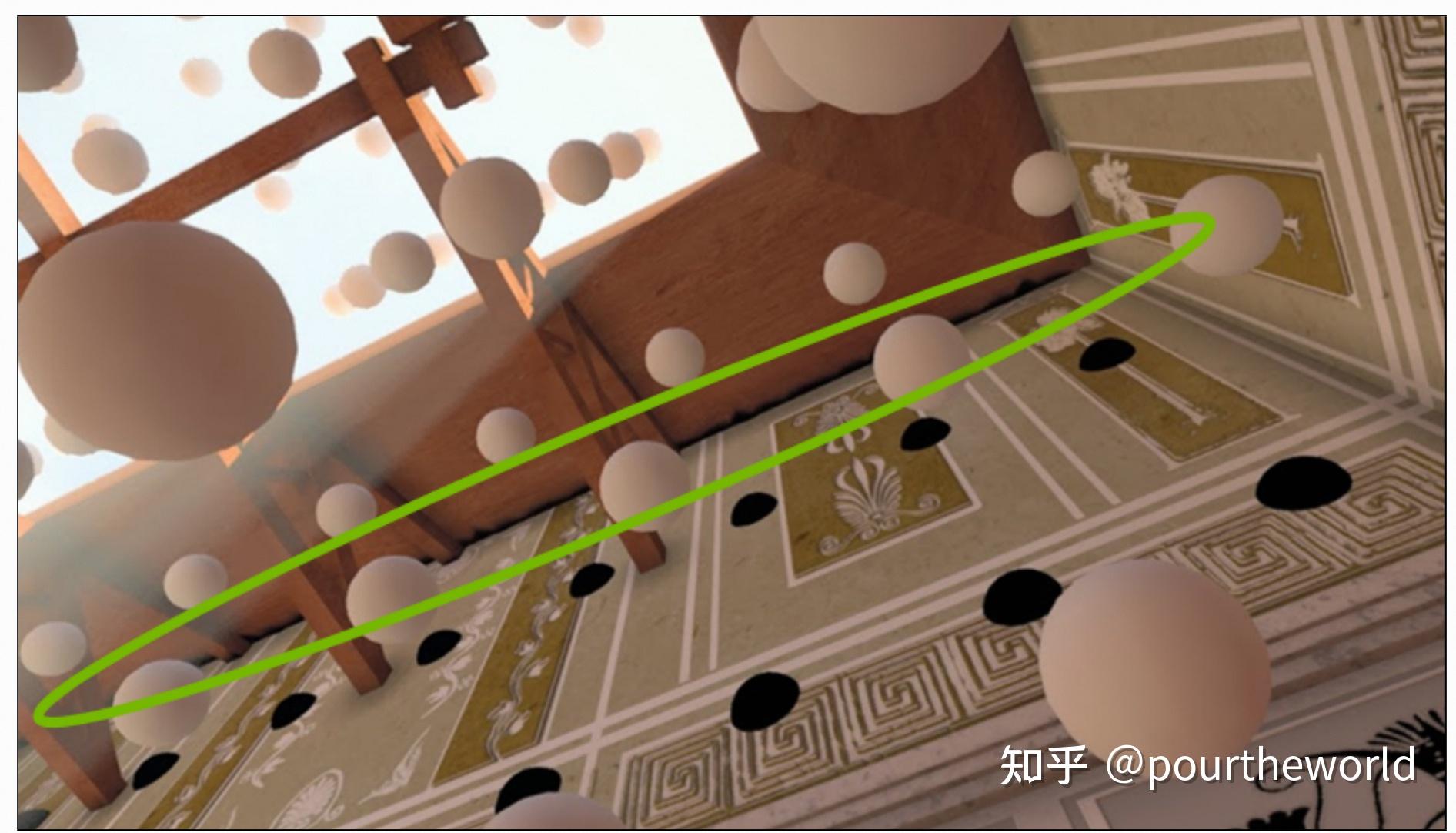 The black probes are correctly dark, but are not contributing to the finalimage. 论文 5 Probe-position Adjustment of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production 的改进方案很简单:
The black probes are correctly dark, but are not contributing to the finalimage. 论文 5 Probe-position Adjustment of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production 的改进方案很简单:
在初始化阶段,根据每个探针可以看到最近的背面 (由探针中心发出射线相交某个表面,通过点乘判断是否为背面) ,调整探针远离当前可能嵌入的几何体 (对应探针嵌在墙内,最近的背面一般来源于墙后)。将探针远离可以看到最近的正面 (对应探针离墙很近,因此可以直接远离墙壁)。两个方案均是为了最大化 surface visibility 。 adjusts probes out of the wall and ceiling to remove the leak.Relocate Probes 和 Classify Probes 两个阶段都会用到 Probe Data 纹理数组,引用于 Probe Data 。
adjusts probes out of the wall and ceiling to remove the leak.Relocate Probes 和 Classify Probes 两个阶段都会用到 Probe Data 纹理数组,引用于 Probe Data 。
纹理数组的 slices 同样表示垂直于坐标系上轴的探针平面,平面内部 row 和 column 直接对应 3D grid-space 下平面中的每个探针,texel 则保存了两个信息:
World-space offsets - 保存在 XYZ 通道用于 probe relocation,归一化到 [0, 0.45) 。Probe state - 保存在 W 通道用于 Probe classification 。 A visualization of the Probe Data texture (zoomed) for the Crytek Sponza scene接下来的小节将详细介绍 Relocate Probes 的实现,其中工程代码位于 RelocateDDGIVolumeProbes() ,shader 代码位于 DDGIProbeRelocationCS() 。
A visualization of the Probe Data texture (zoomed) for the Crytek Sponza scene接下来的小节将详细介绍 Relocate Probes 的实现,其中工程代码位于 RelocateDDGIVolumeProbes() ,shader 代码位于 DDGIProbeRelocationCS() 。
进入迭代之前,首先获取迭代所需的变量:
offset - 当前探针在 DDGIVolume 中的 World-space offsets,上文提到过保存在 Probe Data 纹理数组中,三个方向均归一化到 [0, 0.45) 。closestBackfaceIndex / closestFrontfaceIndex / farthestFrontfaceIndex - 分别是由当前探针中心发出的光线能相交到最近背面、最近正面、最远正面对应的光线索引。closestBackfaceDistance/ closestFrontfaceDistance/ farthestFrontfaceDistance - 分别是由当前探针中心发出的光线能相交到最近背面、最近正面、最远正面和探针中心之间的距离。backfaceCount - 探针中心发出的光线击中背面的次数。进入迭代,根据 RayData 中已经保存的每条光线击中表面与探针中心的距离,以此判断击中的是背面还是正面,并更新相应变量:
退出迭代,根据迭代后的变量来更新 offset 。
首先判断击中背面的次数是否超过了 probeFixedRayBackfaceThreshold ,超过则认定当前探针嵌在某个几何体内部。根据 closestBackfaceIndex 获取 closestBackfaceDirection,沿着该方向远离一段距离:
如果当前探针没有嵌在几何体内,且当前探针已记录的最近正面小于预设的 probeMinFrontfaceDistance ,意味着当前探针离最近正面太近了,需要远离。
在实行远离最近正面方案之前,需要先判断已记录的最近正面和最远正面对应方向之间的夹角是否超过 90° :
如果超过,意味着当前探针向最远正面移动可以有效增加 surface visibility 。如果未超过,意味着当前探针向最远正面移动的同时,同样会靠近最近正面,那么没有移动的意义。最后一种情况,如果当前探针最近正面大于预设的 probeMinFrontfaceDistance,意味着当前探针并没有过于靠近某个几何体,适当的往 zero offset 的方向靠近即可:
Probe classfication 旨在通过是否对最终光照结果作出贡献来分类 DDGIVolume 中的探针,并 disable 那些没有作出贡献的探针的 GPU 工作流程,从而实现性能提升。
这个概念始于 6 Probe States of Scaling Probe-Based Real-Time Dynamic Global Illumination for Production ,但最终实现中简化为了 Probe Classification 。
这个阶段的算法步骤相对简单:
检查当前探针是否嵌在几何体中 (类似 Relocate Probes 中检查探针光线击中背面的次数),若超过预设次数直接设置当前探针状态为 inactive 并退出。检查当前探针是否邻近正面几何体 (从当前探针中心发出光线与邻近探针平面相交并记录距离),若相交距离小于等于保存在 Ray Data 中的击中距离 (当前探针中心与光线方向路径上击中点之间的距离),则意味着当前探针周围有邻近物体,设置当前探针为 active 并退出;若所有光线方向上的相交距离均大于击中距离,意味着当前探针周围没有邻近物体,设置当前探针状态为 inactive 并退出。
最近更新小说资讯
- 特别推荐 收藏共读|朱永新:新教育实验二十年:回顾、总结与展望(上)
- 网红+直播营销模式存在的问题及建议
- 火星探测、卫星搜寻、星球大战,你有怎样的“天问”?
- 希腊男性雕塑 希腊人的美学,那里越小越好
- 枸杞吃多了会怎么样 成年人一天可以吃多少
- “妈妈和哥哥被枪杀后,我变成地球最后一个幸存者”:热搜这一幕看哭了……
- 节约粮食倡议书400字作文
- 祖孙三代迎娶同一个妻子,本以为是笑话,没想到却是真实故事
- 进击的中东,唯有一声叹息
- 唐山性感老板娘不雅视频曝光,少妇贪心,少男痴情!注定两败俱伤
- 【盘点】5G时代下,相关专业有哪些?
- 毁三观的旧案, 双胞胎兄弟交换身份与女友发生关系, 终酿伦理纠纷
- 腾格尔在当今乐坛的地位如何(腾格尔为什么能)
- 小贝日本游,11岁小七身材发育成熟,穿紧身衣有曲线,瘦了一大圈
- 甩三大男神前任,恋上有家室老男人拿下影后,她人生比电影还精彩
- 女英雄为国为民,先后嫁给3人,却落个精神崩溃服毒自尽
- 墨西哥超大尺度神剧,四对超高颜值情侣一言不合竟开启“换妻游戏”?
- 妈妈对小学孩子的成长寄语
- 面向未来的工程伦理教育
- 用大宝贝帮妈妈通下水道好吗
- 第36章:家庭伦理
- 华东师范大学心理学考研看这一篇就够了
- 李玉《红颜》 电影带来的世界44
- 微改造 精提升⑩ | “渔民画云码头”,探索传统非遗产业化发展新路径
- 清朝皇帝列表及简介 清朝历代皇帝列表