 手机访问:wap.265xx.com
手机访问:wap.265xx.com为什么人脑能完成「复杂」的推理?
像通过一些蛛丝马迹判断主人在不在家、眼前的两个人关系怎么样,甚至像神探夏洛克里的卷福一样见微知著,为什么人脑可以完成如此复杂的推理?这种能力可以后天训练的到吗?本题来自知乎圆桌 ? 认知解码,更多认知科学相关的话题欢迎关注讨论。
前几年特别喜欢看一档叫「最强大脑」的综艺。14年的时候有一个重量级嘉宾参与录制引起了我的关注,就是现任北京大学心理与认知科学学院院长方方老师。
方方老师在节目录制后发表了论文《〈最强大脑〉背后的心理学、认知科学和脑科学》,收录在《中国科学:生命科学》2016年第10期。文章选取了看字知笔画、知觉学习、多客体追踪、生物运动四个项目进行了解读。
某种程度上讲,福尔摩斯的思维模式在算是最强大脑模式之一了,这篇科普性的文章应该能给一个大概看得懂的粗浅答案。
“扒鸡大妈”赵淑芳在最强大脑节目中表演了“看字知笔画”的能力,即随意给出一句话(节目中要求在12个汉字以内),她都可以快速报出这句话中所包含的所有汉字的笔画数之和(图1A).这一能力让在场的科学评审感到惊叹,一时难以进行评价和打分. “扒鸡大妈”赵淑芳
“扒鸡大妈”赵淑芳
为什么数笔画这种看上去平淡无奇的能力却能让人感到惊讶呢?在日常学习和使用汉字的过程中,人们往往首先是对汉字的字形和字音进行加工,然后通过字形和字音从长时记忆中提取汉字的意义,产生语义的激活,此即所谓的语义通达过程[1].
然而除了字形、字音、字义信息外,汉字中的笔画数量信息在日常生活中却很少被用到,因此人们一般并不会对笔画数量的信息进行加工和记忆.需要数笔画的时候,往往需要一笔一画地重现汉字书写过程,而这一过程也就需要较长的时间才能完成.
那么,“扒鸡大妈”是如何做到在如此短的时间内报出汉字笔画数的呢?对此提出了两种可能的假设:
(1)记忆假设,即“扒鸡大妈”可能是在日常生活中以内隐或外显的方式加工和记忆了汉字笔画数量的信息,然后在“数笔画”的表演中,直接将笔画数量信息从记忆中提取出来,这和人们对字形、字音、字义的记忆类似;
(2)视觉加工假设,即“扒鸡大妈”可能是因为对汉字有较好的早期视觉识别与加工的能力,因此能够很快地数出汉字的笔画数量.研究显示,白闭症谱系(autism spectrum disorder,ASD)患者中有一些人就具有这种超乎常人的视觉加工与数量辨别能力(numerosity estimation)[2][3][4].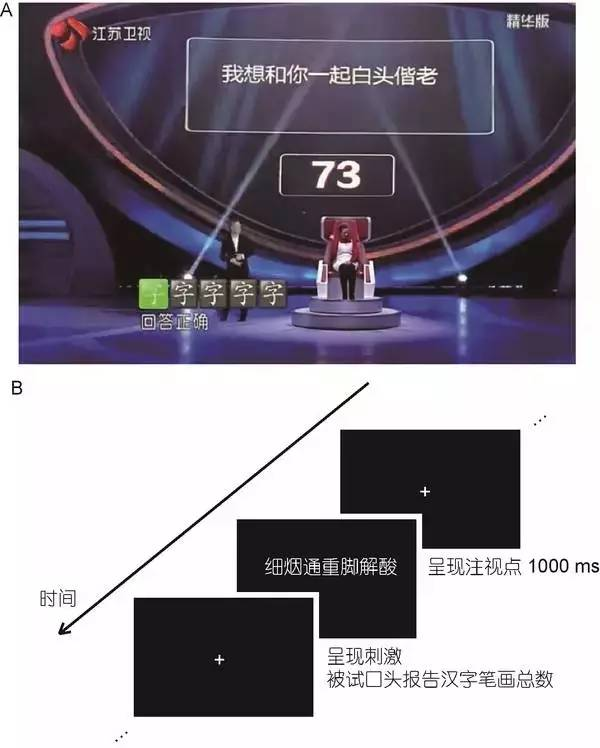 图1 “扒鸡大妈”赵淑芳在《最强大脑》中的表演项目(A);实验研究中的主要实验流程(B)
图1 “扒鸡大妈”赵淑芳在《最强大脑》中的表演项目(A);实验研究中的主要实验流程(B)
为了探究原因和检验以上两种假设,从全国各地找到了多位具有这种“看字知笔画”能力的被试进行了实验研究(图1B).结果表明,这些被试识别汉字的速度与常人没有差异,也就是说被试与正常人相比并不存在对汉字的早期视觉加工优势,因此也就否定了上文中提出的视觉加工假设.同时,功能性磁共振成像(functional Magnetic Resonance Imaging,fMRI)实验数据表明,被试在数笔画过程中的反应越快,与记忆相关脑区左侧海马(left hippocampus)的激活就越强,存在显著的负相关.这一结果为上文中提到的记忆假设提供了直接的证据支持.
除了脑成像的结果外,其他行为实验的结果也为记忆假设提供了问接的证据支持.
首先,发现日常生活中汉字出现的频率显著地影响了被试数笔画的速度:对经常出现的高频汉字数笔画所需要的时间明显低于低频汉字、假字、伪字以及繁体字.这与被试对汉字笔画数量信息的学习记忆机制是吻合的,也就是说被试对于日常生活中经常出现的高频汉字进行了更多的学习与记忆,因此数笔画的速度也就更快.
其次,使用眼动仪追踪了被试数笔画过程中的眼睛注视点,发现被试在数笔画过程中眼动较少,没有明显的注视点移动现象,几乎是看一眼汉字就立即报告出了笔画数目.而对照组被试(即普通人)在数笔画时则会在汉字区域有较多的眼动轨迹,表明注视点往跟随笔画的书写轨迹.这一结果反映了两组被试的数笔画方式存在很大差异,即正常人在数笔画的过程中需要追踪和扫描汉字字形中的每一个笔画,而“扒鸡大妈”们在数笔画时则没有对于汉字字形的精细序列加工,也就是说他们并不是一笔一画数出来的笔画数目,而更可能是在看到汉字后直接从记忆中提取该字的笔画数量信息.
除了对常见汉字笔画的学习与记忆外,实验结果表明被试也会采取一些策略来帮助计算汉字的笔画数日.从行为实验中发现,当呈现由汉字的偏旁部首组成的假字和伪字时,被试数笔画所需要的时间也明显增大.由事后访谈得知,被试在这些情况下会将汉字拆分成熟悉的、已知笔画数目的汉字部件(如部首等),然后再相加得到整个汉字的笔画数.值得注意的是,在实验中发现被试计算加法的心算速度明显高于控制组,而这一心算能力一方面能帮助他们在使用策略时更快地得到汉字部件的笔画数之和,另一方面也可以帮助他们更快地完成多个汉字的数笔画任务.
在确认了记忆在“看字知笔画”这一能力中的重要作用后,不禁要问,为什么他们会在日常生活中加工和记忆这些看似无用的汉字笔画数目信息呢?
我们猜测这一能力的产生可能与自闭症(autism spectrum disorder,ASD)和强迫症(obsessive compulsory disorder,OCD)的相关特质有关.除了参加行为与脑成像实验外,被试也被要求填写了自闭谱系量表(autism-spectrum quotient,AQ)和强迫行为量表(obsessive-compulsive inventory-revised.OCI-R)来评定被试可能存在的自闭和强迫倾向.量表的分析结果表明,尽管这些被试者都没有达到自闭症和强迫症的诊断标准,但是他们在这两个量表上的得分与数笔画所需要的时间均存在显著的负相关.即倾向越强,数笔画的速度越快.
前人研究发现,一些自闭症患者往往会倾向于对客体的局部细节特征进行加工[4],而在本实验中,被试虽然没有被诊断为自闭症,但是这种认知加工风格的倾向使得被试能够更加容易地从高度结构化的信息中获得有关单个元素的知识并进行精确记忆,有利于他们关注汉字的笔画数目.类似地,尽管这些被试也没有被诊断为强迫症,但强迫性行为的特点和倾向仍然会使得他们在有限的范围内表现出强烈兴趣和重复性行为,例如学习和记忆汉字的笔画数目,这种兴趣也很可能会作为动机来提高被试加工和记忆笔画数量信息的积极性.总而言之,这些认知行为的倾向可以在一定程度上解释“扒鸡大妈”“看字知笔画”能力的根源.
对“看字知笔画”这种能力进行研究在心理学领域具有一定意义.例如,基于学者症候群(savants yndrome)的研究结果,扒鸡大妈所具有的这种“看字知笔画”能力与学者症候群个体所表现出来的一些能力就存在一定相似性.学者症候群一般指的是患有严重心理障碍或精神发育迟滞的个体在某些特殊任务上却能表现出远超正常人能力的现象[5].
这些特殊任务上的超常能力一般包括视觉艺术(尤其是绘画)、音乐演奏以及一些其他的特殊计算能力,如日历计算(calendar calculating,即给出一个日期就能说出是星期几)等[5][6].已有研究中对学者症候群背后机制的解释同样囊括了学习与记忆、策略的习得以及自闭症相关的认知特质等几个方面[6][7],与在“看字知笔画”的人群中的发现非常相似.
然而在早期的研究案例中,研究者往往特别关注精神发育迟滞以及低智商与特殊能力之间可能存在的关系,甚至将精神发育迟滞以及低智商当作学者症候群成立的必要条件[5],但Heaton和Wallace[7]却在综述中提出学者症候群更可能是与自闭症或其他心理障碍背后的知觉加工特点存在密切的关系.对“看字知笔画”能力的研究从正常人的角度证明了Heaton和Wallace[7]的观点,暗示即使没有达到诊断的标准,自闭症与强迫症相关的认知加工特点与学者症候群类似能力存在一定关联.因此这一结果对学者症候群以及自闭症、阿斯伯格综合征(Asperger syndrome)等方面的研究都具有重要的意义.
同时,“看字知笔画”能力与自闭和强迫行为倾向之间的相关性也再一次说明认知加工特质在人群中是一个连续变化的谱系分布,因此不能简单地将个体分为正常和非正常两个类别;人群中有些人虽然还没有达到心理障碍的诊断标准,但相关的人格特质和认知加工风格可能对其认知能力产生一定的影响. “捕风者”曹全全
“捕风者”曹全全
“捕风者”曹全全在节目中的挑战项目是在一个电影片段中插入另一部电影的一帧,他需要分辨这一帧画面来自于哪部电影(图2A).胶片电影的放映速度是每秒24帧,因此在电影放映过程中,这一帧只在挑战者面前出现了1/24s,约42ms.一般人(如在场嘉宾)在这42ms的时间内只能看到画面“闪”了一下,而曹全全则可以在这段时间内分辨出画面的内容,再判断这一画面来自于哪一部电影.除对电影画面的记忆能力之外,他的毫秒级别的视觉辨别能力似乎更加让人惊叹.
然而事实上,普通人的视觉系统在经过足够的练习后,几乎都可以达到这种辨别能力,而这种练习过程在心理学研究领域中则被称为知觉学习(perceptual learning).
在知觉学习的经典实验范式中,由Karni和Sagi[8]最早使用的纹理辨别任务(texture discrimination task,TDT)与曹全全的挑战最为相似,同样都是在极短的时间内呈现刺激然后进行视觉辨别和判断.
在TDT范式中,在电脑屏幕正中的注视点位置显示以一定角度旋转的字母“T”或“L“,该字母周围为电脑生成的纹理刺激,包括水平线条组成的背景刺激和3条45°角倾斜的线条组成的前景刺激(即目标刺激),目标刺激的排列方向分为水平和竖直两种,呈现于视野中固定的某个象限中,呈现位置随机,而被试的任务就是对前景刺激的排列方向进行判断. 图2 “捕风者”曹全全在《最强大脑》中的表演项目(A);经典知觉学习研究中使用的实验刺激(B);TDT实验范式(C)
图2 “捕风者”曹全全在《最强大脑》中的表演项目(A);经典知觉学习研究中使用的实验刺激(B);TDT实验范式(C)
在实验过程中,单个试次首先呈现250~300ms空屏,然后呈现10ms刺激,经过一段时间间隔(stimulus-to-mask-onset asynchrony,SOA)后呈现100ms掩蔽刺激(图2B).实验刺激呈现时,被试首先对中央字母进行判断(即中央字母是“T”还是“L”),以保证被试在刺激呈现过程中不会发生眼动,只能用周围视野对目标刺激的方向进行辨别;然后当掩蔽刺激呈现时,被试对目标刺激的排列方向(即“水平”还是“竖直”)进行报告(图2C).因为视觉暂留的原因,可以认为实验测得的SOA阈限即为被试视觉识别所需要的最短时间.
在训练的开始阶段,被试的SOA阈限为100~150ms,但是经过5~10天的训练(每天的训练试次为1000个左右)后,被试的阈限可以下降50%~70%,最后稳定在40~50ms左右[8],即一张图片闪过40~50ms,被试便能辨别图片中前景刺激的排列方向,从视觉辨认角度来说,TDT的实验任务可能比曹全全的挑战任务还要困难,因此这一结果证明通过10天左右的知觉学习训练便可以让每一个普通人具备类似曹全全的视觉辨别能力.
除了纹理辨别任务外,知觉学习还可以通过训练提高人们对其他基本视觉特征的辨别能力,包括视觉对比度、空间视敏度、刺激朝向、运动方向等[9][10][11][12]. 除了视觉外,在触觉和听觉方面也存在知觉学习的效应,如通过训练提高手指对振动频率的辨别能力[13]以及听觉系统对声音时长的辨别能力[14]等.
早期的研究发现,这种学习发生在较低级的感觉皮层,如初级视觉皮层(V1)[15]等,并且具有较强的特异性,如对某一方向的视觉刺激所进行的知觉学习效果并不能迁移到其他方向的刺激上[9],甚至在某一个视网膜位置上进行的学习也并不一定能迁移到其他视网膜位置上[8][16]. 然而后来的研究认为较高级的皮层区域对于知觉学习也具有自上而下的影响和调控[17][18].
知觉学习的研究对心理学、认知科学和脑科学都具有重要的意义,因为它是大脑可塑性的具体表现.已有的研究表明,对光栅刺激朝向的知觉学习可以改变早期视觉皮层(V1)中神经元对训练朝向的敏感性[19],而对运动方向的知觉学习则同样能使得大脑中与视觉运动相关的神经元敏感性增加[20][21].
此外,研究知觉学习对于感觉训练和感觉系统神经性疾病的康复也有着重要的指导作用,尤其是对成年弱视(amblyopia)患者的治疗,一般认为青少年在12岁以后,视皮层发育相对停滞,对弱视的治疗效果较差,然而知觉学习的研究则证明了对于成年人而言,视觉皮层仍然是具有可塑性的,这结果给成年弱视患者的治疗带来了曙光,进一步的研究发现,弱视患者的视觉系统与正常人相比可能具有更强的可塑性和可迁移性[22][23],这也为成年弱视患者的知觉学习疗法提供了进.步的证据和支持. 苏清波
苏清波
在第三季的节目中,苏清波第二次挑战的“奔跑的力量”被嘉宾公认为本季难度最高的项目. 这项挑战中,50位奔跑者在巨型广场上自由跑动15min,选手需要在这段时间内同时观察和记忆50条奔跑路线,随后绘制出嘉宾指定的任一条路线(图3A). 苏清波的精彩表现令所有人惊叹不已,他在这里展现出的是远远超过常人的多客体追踪(multiple-objecttracking,MOT)能力.
在日常生活中,人们常常需要同时关注和追踪多个物体. 足球运动员必须追踪队友和对手的跑位,以及球的位置;警察需要同时追踪人群中多个个体的行动,找出潜在的安全隐患. 近30年来,科学家针对多客体追踪背后的心理机制做了大量探索,发现了一些行为及脑成像方面的规律.  图3 苏清波在《最强大脑》节目中的挑战项目“奔跑的力量”(A);多客体追踪研究中的经典范式(B)
图3 苏清波在《最强大脑》节目中的挑战项目“奔跑的力量”(A);多客体追踪研究中的经典范式(B)
1998年,Pylyshyn和Storm最早提出了多客体追踪的研究范式[24]. 实验中,多个外观相同的物体在长方形区域内做随机运动. 运动开始前,其中几个物体被标记为目标项(target item),另一些则称为干扰项(distractor item). 随后所有物体恢复成外观一致,并随机运动7~15s. 最终被试需回答某个指定的物体是否为目标项(图3B).
研究发现,被试通常能同时追踪最多四项物体,这一上限被称为追踪容量(tracking capacity),追踪容量受到多种因素影响:追踪时间越长,物体运动速度越快,目标项和干扰项距离越小,这些因素都会降低追踪容量[25].
节目中,苏清波在长达15min的时间内追踪50项目标,不论是追踪时间还是数量都远远超过人类的平均水平. 当然选手在完成挑战时和标准的实验测试不一样:首先这50个目标不是同时显示在屏幕上,而是有一定的先后顺序. 其次,选手提前记忆了大量信息,包括整个场地的路径和可能的目标轨迹. 再次,目标本身有编号,而不是像在实验条件下所有目标都是一样的外观. 即使有这些因素能降低难度,选手还是展现了超人一等的记忆能力和多客体追踪能力.
多客体追踪任务究竟用到了何种基本认知功能?科学家认为,多客体追踪和视觉注意(visual attention)密切相关. 人脑的注意资源是有限的,如果将注意比作一盏聚光灯,那么我们的聚光灯在同一时刻只能照亮视野中的一小块区域. 然而多客体追踪的硏究暗示,人类的注意可能是多盏聚光灯并行工作,照亮视野中的不同区域,这一假说被称为多焦点注意(multifocal attention),有部分科学家支持该假说[25]. 另一部分研究者[24]认为,人脑注意的焦点只有一个,但是可以在不同物体之间切换;他们进一步提出注意是在物体的视觉索引(visual index)间进行切换,索引形成于早期视觉加工阶段,这一假说被称为切换模型(switch model)或前注意索引理论(preattentive indexes theory). 以上两种学说均有充分的实验证据支持,多客体追踪的机制尚无定论.
多客体追踪是否可能被学习?心理学家的答案是肯定的,但需要长时间或在特定条件下训练. 2006年,Green和Bavelier发现电子游戏玩家的追踪容量比非玩家多2项,这可能和玩家在游戏中需主动分配注意资源有关[26]. 随后他们让非游戏玩家进行一个月的“第一人称”射击游戏训练,结果发现长时间的注意训练显著提高了多客体追踪容量. 另一项研究发现,当训练阶段和最终测试阶段的目标项的轨迹完全相同时,短时间的训练也能够提高追踪成绩[27].
人脑的哪些区域参与了多客体追踪任务?科学家借助脑成像技术,发现和多客体追踪有关的脑区包括上顶叶(superior parietal lobule,SPL)、额叶眼区(frontal eye fields,FEF)、顶内沟(intraparietal sulcus,IPS)和顯中回运动区(middle temporal complex,MT+)[28][29][30][31],其中,SPL和FEF可能和控制眼跳有关,MT+负责表征运动物体的位置,IPS可能和注意有关.
第三季节目中最大的争议来自于苏清波挑战的“光点美人”项目. 挑战过程中,选手首先现场观看一段集体舞. 每位成员的舞蹈动作被记录之后以光点运动的形式呈现出来,选手需要找出指定成员对应的光点信息(图4A). 该项挑战最终得到的难度系数分并不高,嘉宾对此感到难以理解. 那么,这项任务的难度究竟如何?它背后的心理学现象是什么呢?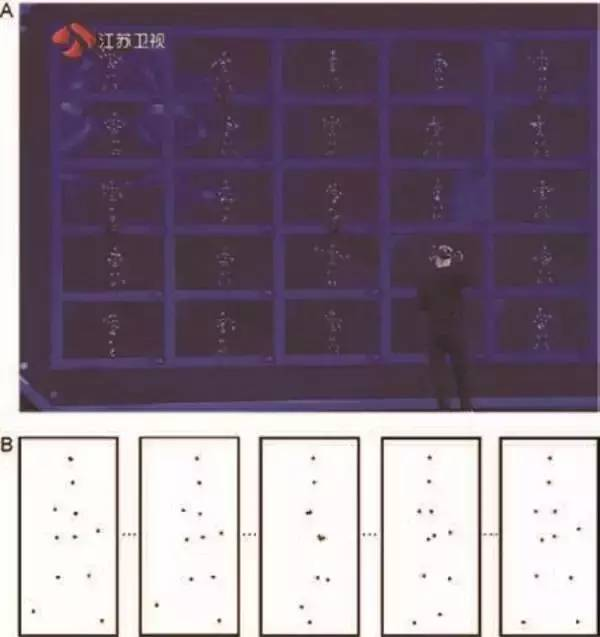 图4 苏清波在“最强大脑”节目中的挑战项目“光点美人”(A);生物运动经典研究中使用的模拟人类行走的光点运动刺激(B)
图4 苏清波在“最强大脑”节目中的挑战项目“光点美人”(A);生物运动经典研究中使用的模拟人类行走的光点运动刺激(B)
日常生活中,我们有时看不清远处人的面孔,但是仅凭走路姿态就能判断出这个人是谁. 我们是凭借生物运动(biological motion)信息来帮助识别的. 生物运动是人类和动物固有的运动模式,如行走、奔跑和舞蹈等. 瑞典心理学家Johansson(1973年)首次使用光点动画技术,将运动模式从外形轮廓特征中突显出来. 他在人体的一些重要关节处贴上信号灯,拍摄人在黑暗房间中完成各种运动时信号灯的运动轨迹,由此得到了光点运动序列(图4B)[32],观察者仅仅根据这些光点就能识别出人的运动.
进一步研究发现,除了动作信息外,人们还能从光点运动中提取其他信息特征,如人物的性别[33]、s身份(自己、朋友或陌生人)[34]和情绪[35]等. 即使在光点运动序列中加入噪声点[36],观察者仍然具有极高的识别正确率. 以上证据都表明,人类对于生物运动信息极为敏感,很擅长识别光点运动刺激[37]. 另外,在鸽子和鸡等动物上也发现了对生物运动信息的偏好[38][39],说明这可能是一种跨种系存在的普遍现象.
人类对生物运动的识别能力,究竟是先天具备还是后天习得的呢?研究者发现,对生物运动信息的识别能力在出生两天的婴儿中即已经体现[40]:新生儿能够区分生物运动和随机光点运动;相比于倒置的生物运动,新生儿更偏好正立的生物运动. 上述证据表明,对生物运动的检测是人类视觉系统的相对天生的固有能力. 在进化过程中,人类和动物形成了对种群中其他个体更加关注的偏好. 与此同时,随着儿童年龄的增长,对生物信息的检测能力逐渐增强,到5岁时达到成人水平[41].
人脑的哪些区域参与了生物运动信息的加工?脑成像研究发现,光点运动序列相比于随机点运动更多地激活了右侧颞上沟后部(posterior superior temporal sulcus,pSTS)以及杏仁核(amygdala)[42]. 对单侧中风患者的研究发现,颞上(superior temporal)和运动前区(premotor frontal area)的切除严重损害了生物运动信息的识别能力[43].
人类和动物天生就擅长处理生物运动信息,大脑中也存在专门加工生物运动信息的结构. 虽然上述的科学发现使得苏清波挑战的“光点美人”的项目难度不高,但这恰恰也说明人类大脑的强大之处. 人脑中存在许多负责某一特定功能的模块化结构,使我们能够轻松地完成各种人类独有的、看似神奇的任务.
我们能够在极短时间内仅凭走路姿态识别他人,正是得益于大脑pSTS区对生物运动信息的自动化加工. 类似的模块化结构还有负责加工面孔信息的梭状回面孔区(fusiform face area,FFA),负责视觉文字加工的视觉词型区(visual wordf orm area,VWFA),负责加工场景信息的海马旁回位置区(parahippocampal place area,PPA)等. 这些脑区帮助我们毫不费力并且精准无误地认出面孔,识别文字,识别场景. 上述这些还只是大脑功能的冰山一角,人类对于大脑的探索刚刚起步,还有更多秘密等待心理学家发现.
人类大脑是一个极其复杂的器官,约860亿个神经元形成的复杂网络上有百万亿数量级别的突触连接,被誉为宇宙中最复杂的1. 5公斤重的物体. 基于它,人类产生了知觉、注意、语言、决策、记忆、意识、情感等心理和认知过程,也产生了以科学和艺术为代表的灿烂的文明. 但是,作为人类理解世界和理解自身的终极科学问题之一,厘清大脑的工作机制的探索征程才刚起步.
在一百多年心理学和近几十年认知科学的努力下,对人类的认知能力及其神经机制取得了一定的进展,这些进展并不为普通民众所熟知. 许多观众惊异于《最强大脑》节目中展示的大脑认知能力,惊异于人类认知能力的多样性、有效性、精确性,这也从一个侧面体现了心理学、认知科学和脑科学科普的重要性.
本文从四个挑战项目入手,详细说明了这些看似神奇任务的背后的心理学实验范式和基本知识. 基于这些分析,得到如下启示. 一是超常能力的背后除了天生优势以外,很多来自于后天的训练. 二是科学发现时常是和常识背离的,如上述研究所证明的那样. 三是科研工作者需要分配出一定的时间和精力,把科学知识转化为大众喜闻乐见的内容和形式传播开来.
对心理学、认知科学和脑科学来说,这有非常重要的现实意义:脑科学与类脑研究在“十三五”规划纲要中被确定为体现国家战略意图的重大科技创新项目和工程之一,“中国脑计划”也箭在弦上. 不仅要在管理层面和学术层面形成合力,更需要向广大民众介绍心理学、认知科学和脑科学的重要性,为学科的长远发展打下基础.
原文链接:《最强大脑》背后的心理学、认知科学和脑科学--《中国科学:生命科学》2016年10期
上一篇:重评《欲孽迷宫》
下一篇:成年礼家长给儿子的一封信5篇
最近更新科技资讯
- 22年过去了,《透明人》依然是尺度最大的科幻电影,没有之一
- 人类基因编辑技术及其伦理问题
- 不吹不黑,五阿哥版的《嫌疑人》能过及格线
- 论Lacan心理公众号的“双标”特质
- 猎罪图鉴:犯罪实录 女性伦理
- 清入关的第一位皇帝是谁,清朝入关后有几位皇帝?
- 描写露台的优美句子
- 谭德晶:论迎春悲剧的叙事艺术
- 中秋节的好词好句
- 《三夫》:一女侍三夫,尺度最大的华语片要来了
- 赛博朋克的未来,在这里
- 文件1091/721/2A:反概念武器实体的一封信件
- 尤战生:哥伦比亚大学点点滴滴
- 韩国最具独特魅力的男演员(安在旭主演的电视剧有哪些)
- 乃至造句
- 请保护好我们的医生,他们太难了
- GCLL06-土木工程的伦理问题-以湖南凤凰县沱江大桥大坍塌事故为例
- 黄金宝典:九年级道德与法治核心考点必背篇
- 【我心中的孔子】伟大的孔子 思想的泰山
- CAMKII-δ9拮抗剂及其用途
- 选粹 | 郑玉双:法教义学如何应对科技挑战?——以自动驾驶汽车为例
- 苍井空37岁宛若少女,携子送祝福遭热讽,下架所有视频母爱无私
- 日韩新加坡怎么对待影视剧中的裸露镜头
- 中西方文化中的颜色词
- 土豪家的美女摸乳师——关于电影《美人邦》